TCP#
TCP 报文格式#
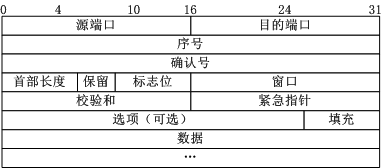
- 序号:Seq 序号,占 32 位,用来标识从 TCP 源端向目的端发送的字节流,发起方发送数据时对此进行标记。
- 确认序号:Ack 序号,占 32 位,只有 ACK 标志位为 1 时,确认序号字段才有效,Ack=Seq+1。
- 标志位:共 6 个,即
URG、ACK、PSH、RST、SYN、FIN等,具体含义如下:URG:紧急指针(urgent pointer)有效。ACK:确认序号有效。PSH:接收方应该尽快将这个报文交给应用层。RST:重置连接。SYN:发起一个新连接。FIN:释放一个连接。
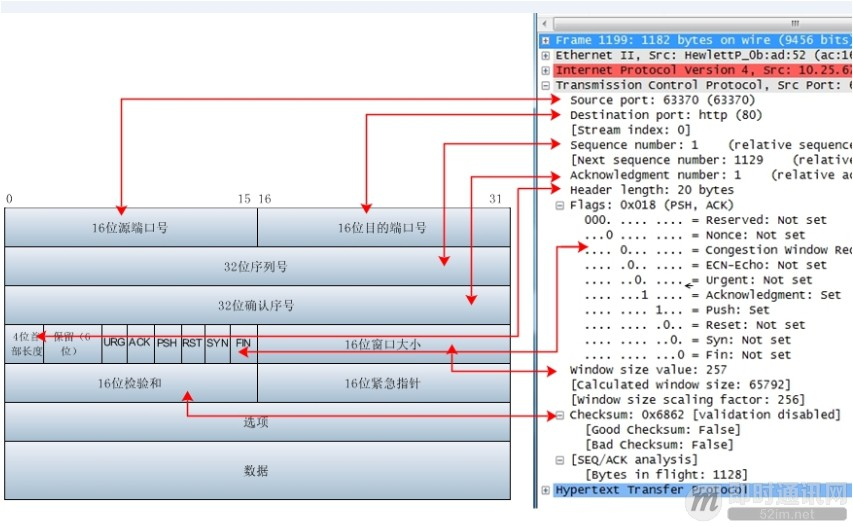
三次握手#
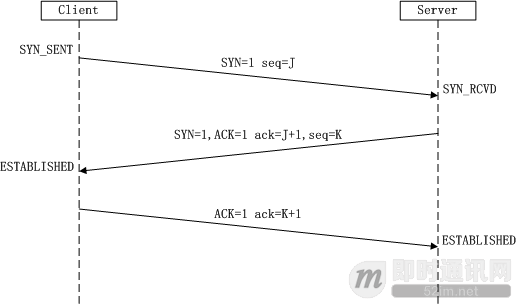
四次挥手#
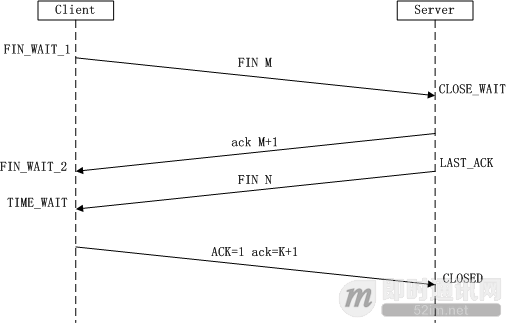
实际中还会出现同时发起主动关闭的情况
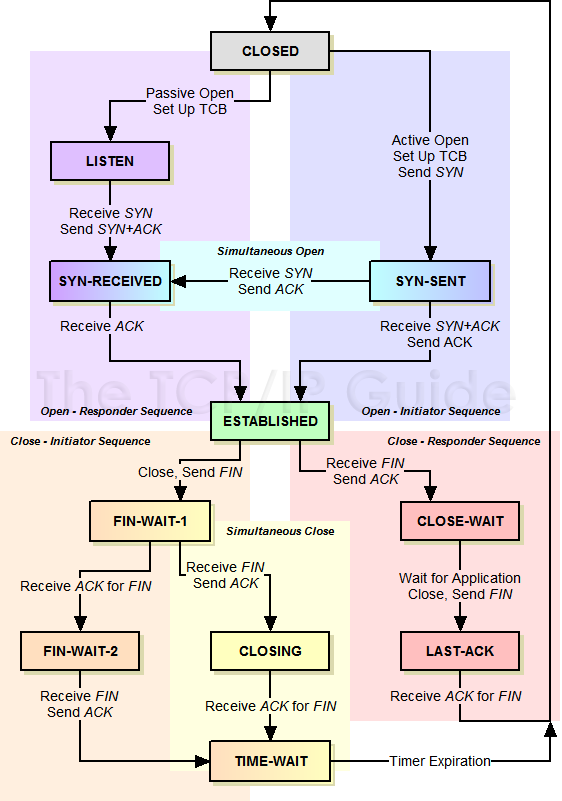
TCP 有限状态机#
The TCP Finite State Machine (FSM)
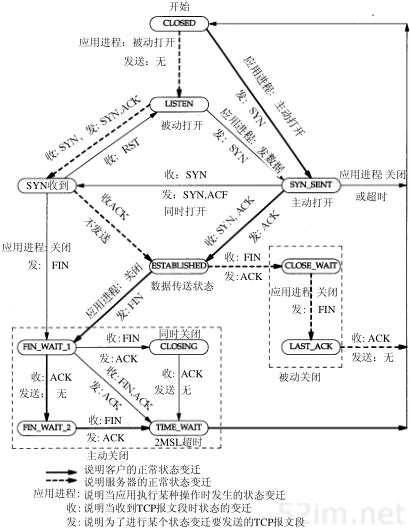
TCP 状态变迁图#
TCP 是全双工的#
TCP 的 RTT 算法#
经典算法(RFC793)#
首先,先采样 RTT,记下最近好几次的 RTT 值。
然后做平滑计算 SRTT(
Smoothed RTT),公式为:SRTT = (α * SRTT) + ((1- α) * RTT)其中的 α 取值在 0.8 到 0.9 之间,这个算法英文叫
Exponential weighted moving average,中文叫:加权移动平均开始计算 RTO。公式如下:
RTO = min [UBOUND, max [LBOUND, (β * SRTT)]]
其中:
- UBOUND 是最大的 timeout 时间,上限值
- LBOUND 是最小的 timeout 时间,下限值
- β 值一般在 1.3 到 2.0 之间。
Karn / Partridge 算法#
Jacobson / Karels 算法#
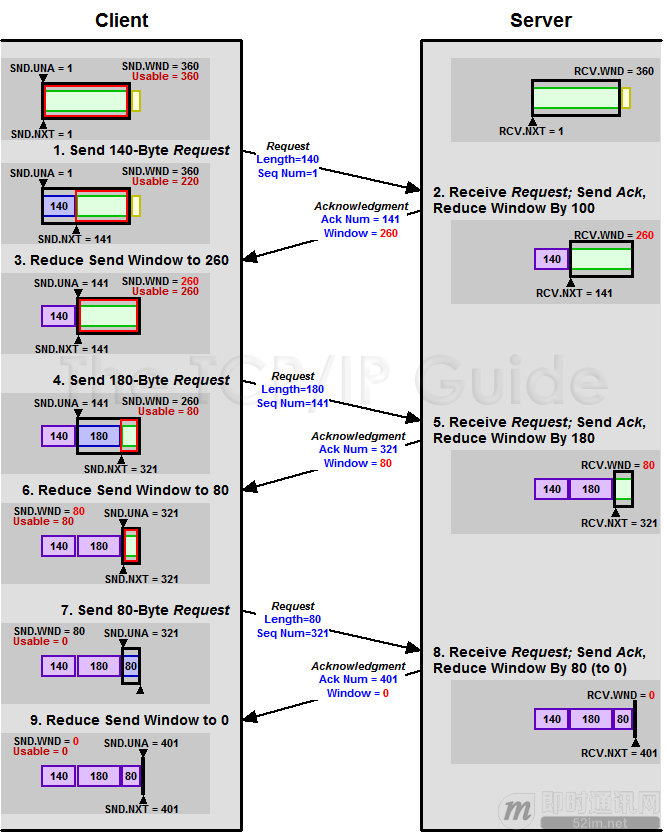
TCP 滑动窗口#
TCP 缓冲区的数据结构
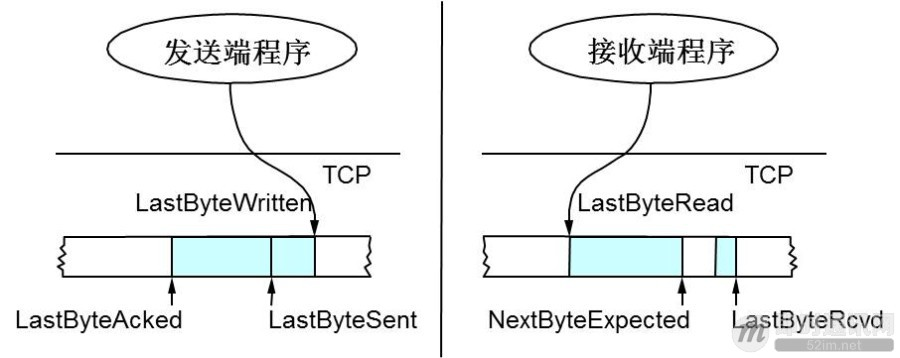
接收端在给发送端回 ACK 中会汇报自己的 AdvertisedWindow = MaxRcvBuffer – LastByteRcvd – 1;
发送方会根据这个窗口来控制发送数据的大小,以保证接收方可以处理
发送方的滑动窗口#
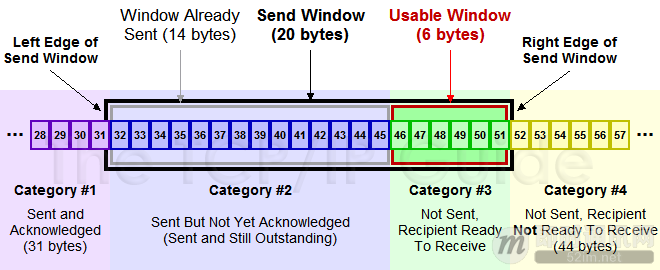
上图中分成了四个部分,分别是:(其中那个黑模型就是滑动窗口)
#1已收到 ack 确认的数据。#2发还没收到 ack 的。#3在窗口中还没有发出的(接收方还有空间)。#4窗口以外的数据(接收方没空间)
接受端控制发送端的图示#
TCP 的拥塞处理#
拥塞控制主要是四个算法:
- 慢启动
- 拥塞避免
- 拥塞发生
- 快速恢复
慢热启动算法 – Slow Start#
慢启动的算法如下 (cwnd 全称 Congestion Window):
- 连接建好的开始先初始化 cwnd = 1,表明可以传一个 MSS 大小的数据。
- 每当收到一个 ACK,cwnd++; 呈线性上升
- 每当过了一个 RTT,cwnd = cwnd*2; 呈指数让升
- 还有一个 ssthresh(slow start threshold),是一个上限,当 cwnd >= ssthresh 时,就会进入 “拥塞避免算法”
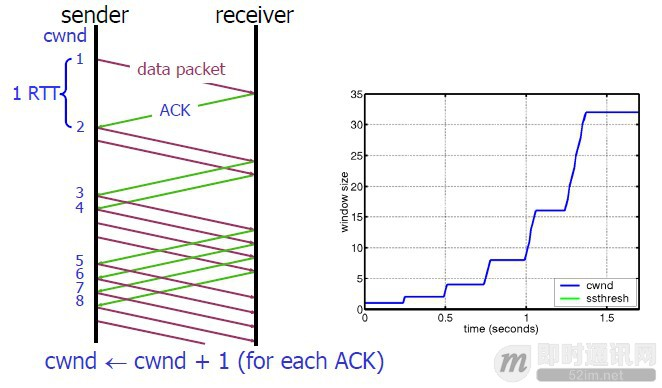
拥塞避免算法 – Congestion Avoidance#
ssthresh(slow start threshold)是一个上限, 当 cwnd >= ssthresh 时,就会进入 “拥塞避免算法”。
一般来说 ssthresh 的值是 65535,单位是字节,当 cwnd 达到这个值时后,算法如下:
- 收到一个 ACK 时,cwnd = cwnd + 1/cwnd
- 当每过一个 RTT 时,cwnd = cwnd + 1
这样就可以避免增长过快导致网络拥塞,慢慢的增加调整到网络的最佳值。很明显,是一个线性上升的算法。
拥塞状态时的算法#
快速恢复算法 – Fast Recovery#
FACK 算法#
更多拥塞控制请参考论文《Congestion Avoidance and Control》(PDF)
SYN 攻击#
在三次握手过程中,Server 发送 SYN-ACK 之后,收到 Client 的 ACK 之前的 TCP 连接称为半连接(half-open connect),
此时 Server 处于 SYN_RCVD 状态,
当收到 ACK 后,Server 转入 ESTABLISHED 状态。
SYN 攻击就是 Client 在短时间内伪造大量不存在的 IP 地址,并向 Server 不断地发送 SYN 包,Server 回复确认包,并等待 Client 的确认, 由于源地址是不存在的,因此,Server 需要不断重发直至超时,
这些伪造的 SYN 包将产时间占用未连接队列,导致正常的 SYN 请求因为队列满而被丢弃,从而引起网络堵塞甚至系统瘫痪。
SYN 攻击时一种典型的 DDOS 攻击,
检测 SYN 攻击的方式非常简单,即当 Server 上有大量半连接状态且源 IP 地址是随机的,则可以断定遭到 SYN 攻击了,
使用如下命令可以让之现行:
$ netstat -nap | grep SYN_RECV于是,server 端如果在一定时间内没有收到的 TCP 会重发 SYN-ACK。 在 Linux 下,默认重试次数为 5 次, 重试的间隔时间从 1s 开始每次都翻售,5 次的重试时间间隔为 1s, 2s, 4s, 8s, 16s,总共 31s, 第 5 次发出后还要等 32s 都知道第 5 次也超时了, 所以,总共需要 1s + 2s + 4s+ 8s+ 16s + 32s = 2^6 -1 = 63s,TCP 才会把断开这个连接。
解决#
对于正常的请求,你应该调整三个 TCP 参数可供你选择,
tcp_synack_retries可以用他来减少重试次数tcp_max_syn_backlog可以增大 SYN 连接数tcp_abort_on_overflow处理不过来干脆就直接拒绝连接了
问答#
为什么建立连接是三次握手,而关闭连接却是四次挥手呢?#
因为服务端在 LISTEN 状态下,收到建立连接请求的 SYN 报文后,把 ACK 和 SYN 放在一个报文里发送给客户端。
而关闭连接时,当收到对方的 FIN 报文时,仅仅表示对方不再发送数据了但是还能接收数据,己方也未必全部数据都发送给对方了,所以己方可以立即 close,也可以发送一些数据给对方后,再发送 FIN 报文给对方来表示同意现在关闭连接, 因此,己方 ACK 和 FIN 一般都会分开发送。
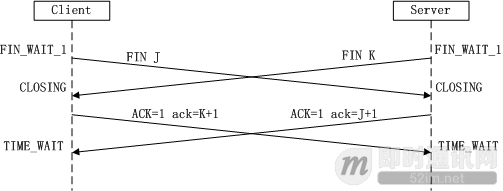
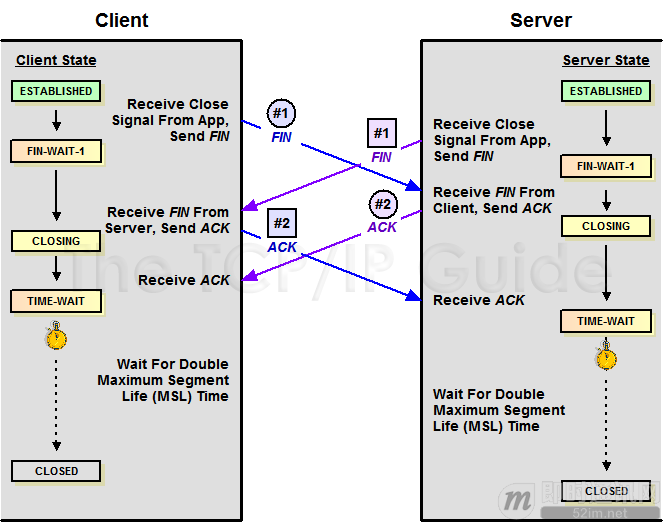
对于 4 次挥手:其实你仔细看是 2 次,因为 TCP 是全双工的,所以,发送方和接收方都需要 Fin 和 Ack。只不过,有一方是被动的,所以看上去就成了所谓的 4 次挥手。如果两边同时断连接,那就会就进入到 CLOSING 状态,然后到达 TIME_WAIT 状态。
下图是双方同时断连接的示意图
单台服务器并发 TCP 连接数到底可以有多少?#
操作系统上端口号 1024 以下是系统保留的,从 1024-65535 是用户使用的。
由于每个 TCP 连接都要占一个端口号,所以我们最多可以有 60000 多个并发连接?
并不是的。这个是客户端的限制,而不是服务端。
系统用一个 4 四元组来唯一标识一个 TCP 连接:{local ip, local port, remote ip, remote port}。
服务端实际只使用了 bind 时这一个端口,说明端口号 65535 并不是并发量的限制
最大 tcp 连接为客户端 ip 数 × 客户端 port 数,
对 IPV4,不考虑 ip 地址分类等因素,最大 tcp 连接数约为 2 的 32 次方(ip 数)×2 的 16 次方(port 数),
也就是 server 端单机最大 tcp 连接数理论上约为 2 的 48 次方。
当然实际上单机并发连接数肯定要受硬件资源(内存)、网络资源(带宽)的限制。
文件句柄限制#
每一个 tcp 连接都要占一个文件描述符,
一旦这个文件描述符使用完了,新的连接到来返回给我们的错误是 “Socket/File:Can't open so many files”。
进程限制#
执行 ulimit -n 输出 1024,说明对于一个进程而言最多只能打开 1024 个文件
- 用户退出后失效:
ulimit -n 1000000 - 重启后失效:编辑 /etc/security/limits.conf 文件
- soft nofile 1000000
- hard nofile 1000000
- 永久修改:编辑 /etc/rc.local,在其后添加如下内容
- ulimit -SHn 1000000
全局限制#
执行 cat /proc/sys/fs/file-nr 输出 9344 0 592026,分别为:
- 已经分配的文件句柄数,
- 已经分配但没有使用的文件句柄数,
- 最大文件句柄数。
但在 kernel 2.6 版本中第二项的值总为 0,这并不是一个错误,它实际上意味着已经分配的文件描述符无一浪费的都已经被使用了 。
我们可以把这个数值改大些,用 root 权限修改 /etc/sysctl.conf 文件:
fs.file-max = 1000000
net.ipv4.ip_conntrack_max = 1000000
net.ipv4.netfilter.ip_conntrack_max = 1000000为什么服务总会抛出一个 connet reset by peer?#
主动关闭方直接发送了一个 RST flags,而非 FIN,就终止连接了。
出现大量 time_wait 状态怎么办?#
TIME_WAIT 状态也称为 2MSL 等待状态。
每个具体 TCP 实现必须选择一个报文段最大生存时间 MSL(Maximum Segment Lifetime)。
它是任何报文段被丢弃前在网络内的最长时间。
我们知道这个时间是有限的,因为 TCP 报文段以 IP 数据报在网络内传输,而 IP 数据报则有限制其生存时间的 TTL 字段。
RFC 793 [Postel 1981c] 指出 MSL 为 2 分钟。
然而,实现中的常用值是 30 秒,1 分钟,或 2 分钟。
对 IP 数据报 TTL 的限制是基于跳数,而不是定时器。
TIME_WAIT 是怎么产生的?#
连接关闭的过程#
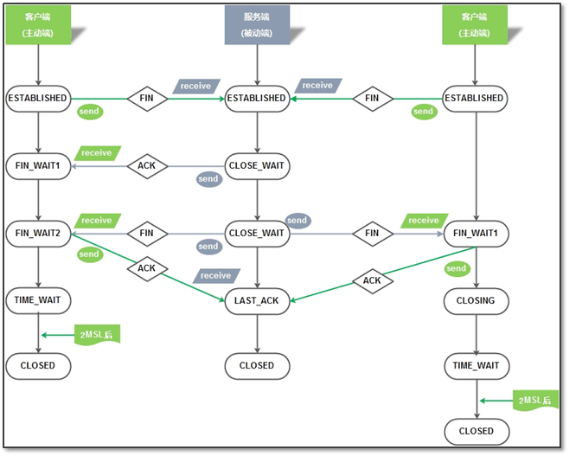
- 主动关闭连接的一方,调用
close();协议层发送 FIN 包 - 被动关闭的一方收到 FIN 包后,协议层回复 ACK;然后被动关闭的一方,进入
CLOSE_WAIT状态;主动关闭的一方等待对方关闭,则进入FIN_WAIT_2状态 - 被动关闭的一方在完成所有数据发送后,调用
close()操作,协议层发送 FIN 包给主动关闭的一方,等待对方的 ACK,被动关闭的一方进入LAST_ACK状态 - 主动关闭的一方收到 FIN 包,协议层回复 ACK,主动关闭连接的一方进入
TIME_WAIT状态;而被动关闭的一方,进入CLOSED状态 - 等待
2MSL时间,主动关闭的一方,结束 TIME_WAIT,进入CLOSED状态
TIME_WAIT 只会出现在主动断开连接的一方#
大量 TIME_WAIT 造成的影响#
- 在高并发短连接的 TCP 服务器上,当服务器处理完请求后立刻主动正常关闭连接。
- 短连接表示 “业务处理 + 传输数据的时间 远远小于 TIME-WAIT 超时的时间” 的连接
- 高并发可以让服务器在短时间范围内同时占用大量端口,
- 而端口有个 0~65535 的范围,并不是很多,刨除系统和其他服务要用的,剩下的就更少了。
- 在实际业务场景中,一般长连接对应的业务的并发量并不会很高
- 这些端口都是服务器临时分配,无法用
SO_REUSEADDR选项解决这个问题
- 内存
- 内核里有一个保存所有连接的 hash table
- 不同的内核对这个 hash table 的大小设置不同,你可以通过 dmesg 命令去找到你的内核设置的大小
- 还有一个 hash table 用来保存所有的 bound ports,主要用于可以快速的找到一个可用的端口或者随机端口
- 不过占用内存很少很少。 一个 tcp socket 占用不到 4k。1 万条 TIME_WAIT 的连接,也就多消耗 1M 左右的内存
- CPU
- 每次找到一个随机端口,还是需要遍历一遍 bound ports 的吧,这必然需要一些 CPU 时间。
- 源端口数量 (net.ipv4.ip_local_port_range)
- TIME_WAIT bucket 数量 (net.ipv4.tcp_max_tw_buckets)
- 文件描述符数量 (max open file)
- 一个 socket 占用一个文件描述符
排查#
查看 TCP 各个状态的数量#
netstat -ant | awk '/^tcp/ {++S[$NF]} END {for(a in S) print (a,S[a])}' | sort -rn -k2TCP 状态含义#
| TCP 状态 | 含义 |
|---|---|
| LISTEN | 服务器在等待进入呼叫 |
| SYN_RECV | 一个连接请求已经到达,等待确认 |
| SYN_SENT | 应用已经开始,打开一个连接 |
| ESTABLISHED | 正常数据传输状态 |
| FIN_WAIT1 | 应用说它已经完成 |
| FIN_WAIT2 | 另一边已同意释放 |
| ITMED_WAIT | 等待所有分组死掉 |
| LAST_ACK | 等待所有分组死掉 |
| TIME_WAIT | 另一边已初始化一个释放 |
| CLOSING | 两边同时尝试关闭 |
| CLOSED | 无连接是活动的或正在进行 |
统计 TIME_WAIT 连接的本地地址#
netstat -an | grep TIME_WAIT | awk '{print $4}' | sort | uniq -c | sort -rn -k1 | head如何尽量处理 TIME-WAIT 过多的问题?#
修改内核文件 /etc/sysctl.conf#
net.ipv4.tcp_syncookies = 1 表示开启 SYN Cookies。当出现 SYN 等待队列溢出时,启用 cookies 来处理,可防范少量 SYN 攻击,默认为 0,表示关闭;
net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将 TIME-WAIT sockets 重新用于新的 TCP 连接,默认为 0,表示关闭;
net.ipv4.tcp_tw_recycle = 1 表示开启 TCP 连接中 TIME-WAIT sockets 的快速回收,默认为 0,表示关闭。
net.ipv4.tcp_fin_timeout 修改系默认的 TIMEOUT 时间然后执行 /sbin/sysctl -p 让参数生效。
/etc/sysctl.conf 是一个允许改变正在运行中的 Linux 系统的接口,它包含一些 TCP/IP 堆栈和虚拟内存系统的高级选项,修改内核参数永久生效。
简单来说,就是打开系统的 TIME-WAIT 重用和快速回收。
如果以上配置调优后性能还不理想,可继续修改一下配置:
net.ipv4.tcp_keepalive_time = 1200
#表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时,改为20分钟。
net.ipv4.ip_local_port_range = 1024 65000
#表示用于向外连接的端口范围。缺省情况下很小:32768到61000,改为1024到65000。
net.ipv4.tcp_max_syn_backlog = 8192
#表示SYN队列的长度,默认为1024,加大队列长度为8192,可以容纳更多等待连接的网络连接数。
net.ipv4.tcp_max_tw_buckets = 5000
#表示系统同时保持 TIME_WAIT 套接字的最大数量,如果超过这个数字, TIME_WAIT 套接字将立刻被清除并打印警告信息。
默认为180000,改为5000。对于Apache、Nginx等服务器,上几行的参数可以很好地减少 TIME_WAIT 套接字数量,但是对于 Squid,效果却不大。此项参数可以控制 TIME_WAIT 套接字的最大数量,避免Squid服务器被大量的 TIME_WAIT 套接字拖死。参考:
nginx 配置问题#
- nginx 在配置 “不启用 keep-alive” 时,会在 http 请求结束时主动断开连接
- 尝试开启 http 的 keep-alive
keepalive_timeout 65; - nginx 与 fast-cgi 的默认连接是短连接
- 修改 nginx 配置使其与 fastcgi 的连接使用长连接
upstream phpserver{ server 127.0.0.1:9000 weight=1; # upstream 中的 keepalive 指定 nginx 每个 worker 与 fastcgi 的最大长连接数 keepalive 100 } - 若 nginx 与 fast-cgi 在同一台服务器上,则使用 unix 域 会更为高效,同时避免了 TIME_WAIT 的问题
proxy_pass 与 fastcgi_pass 的区别#
客户端
--http--> 前端负载均衡 Nginx
--proxy_pass--> 业务服务器 Nginx
--fastcgi_pass--> 业务服务器 php-fpm为什么要有 TIME_WAIT 状态?#
- 可靠地实现 TCP 全双工连接的终止
- 在进行关闭连接四次挥手协议时,最后的 ACK 是由主动关闭端发出的,如果这个最终的 ACK 丢失,服务器将重发最终的 FIN
- 因此客户端必须维护状态信息允许它重发最终的 ACK。如果不维持这个状态信息,那么客户端将响应 RST 分节,服务器将此分节解释成一个错误(在 java 中会抛出 connection reset 的 SocketException)。
- 因而,要实现 TCP 全双工连接的正常终止,必须处理终止序列四个分节中任何一个分节的丢失情况,主动关闭的客户端必须维持状态信息进入 TIME_WAIT 状态。
- 让老的重复分节在网络中消逝
- 在关闭一个 TCP 连接后,马上又重新建立起一个相同的 IP 地址和端口之间的 TCP 连接,后一个连接被称为前一个连接的化身(incarnation),那么有可能出现这种情况,前一个连接的迷途重复分组在前一个连接终止后出现,从而被误解成从属于新的化身。
- 为了避免这个情况, TCP 不允许处于 TIME_WAIT 状态的连接启动一个新的化身,因为 TIME_WAIT 状态持续
2MSL,就可以保证当成功建立一个 TCP 连接的时候,来自连接先前化身的重复分组已经在网络中消逝。
叶王 © 2013-2026 版权所有。如果本文档对你有所帮助,可以请作者喝饮料。