LLM(大型语言模型) #
大语言模型 (英语:large language model,LLM) 是一种语言模型,由具有许多参数(通常数十亿个权重或更多)的人工神经网络组成,使用自监督学习或半监督学习对大量未标记文本进行训练。大型语言模型在 2018 年左右出现,并在各种任务中表现出色。

图片来自:Foundation Large Language Model Stack
开源大语言模型 #
- meta-LLaMa
- OpenLLaMA: openlm-research/open_llama





- LLaMA (
Large Language Model Meta AI) - 7B
- meta-llama/Llama-2-7b
- meta-llama/Llama-2-7b-hf
- meta-llama/Llama-2-7b-chat
- meta-llama/Llama-2-7b-chat-hf
- 13B
- meta-llama/Llama-2-13b
- meta-llama/Llama-2-13b-hf
- meta-llama/Llama-2-13b-chat
- meta-llama/Llama-2-13b-chat-hf
- 70B
- meta-llama/Llama-2-70b
- meta-llama/Llama-2-70b-hf
- meta-llama/Llama-2-70b-chat
- meta-llama/Llama-2-70b-chat-hf
- OpenLLaMA: openlm-research/open_llama
- tiiuae
- 7B
- tiiuae/falcon-7b-instruct
- tiiuae/falcon-7b
- 40B
- tiiuae/falcon-40b-instruct
- tiiuae/falcon-40b
- 180B
- tiiuae/falcon-180B
- tiiuae/falcon-180B-chat
- 7B
- THUDM
- GLM: General Language Model
- 6B
- THUDM/chatglm3-6b-base
- THUDM/chatglm3-6b
- THUDM/chatglm3-6b-32k
- THUDM/chatglm2-6b
- THUDM/chatglm2-6b-int4
- 7B
- THUDM/agentlm-7b
- 10B
- THUDM/glm-10b-chinese
- bigscience
- 560m
- bigscience/bloom-560m
- 1B
- bigscience/bloom-1b7
- 7B
- bigscience/bloom-7b1
- 3B
- bigscience/bloom-3b
- 176B
- bigscience/bloom
- 560m
- Baichuan
- 7B
- baichuan-inc/Baichuan2-7B-Base
- baichuan-inc/Baichuan2-7B-Chat
- baichuan-inc/Baichuan2-7B-Chat-4bits
- baichuan-inc/Baichuan2-7B-Intermediate-Checkpoints
- baichuan-inc/Baichuan-7B
- 13B
- baichuan-inc/Baichuan-13B-Base
- baichuan-inc/Baichuan2-13B-Base
- baichuan-inc/Baichuan-13B-Chat
- baichuan-inc/Baichuan2-13B-Chat
- baichuan-inc/Baichuan2-13B-Chat-4bits
- 7B
大模型应用工具 #
- langchain-ai/langchain





- run-llama/llama_index





- deepset-ai/haystack





- microsoft/TaskMatrix





- microsoft/semantic-kernel





BERT #
Bidirectional Encoder Representations from Transformers





微调 #
预训练大语言模型的三种微调技术总结:
- fine-tuning
- Fine-tuning 的基本思想是采用已经在大量文本上进行训练的预训练语言模型,然后在小规模的任务特定文本上继续训练它。
- parameter-efficient fine-tuning
PEFT- 在尽可能减少所需的参数和计算资源的情况下,实现对预训练语言模型的有效微调。
- 3 种技术
- 蒸馏(
distillation),它由 Hinton 等人于 2015 年引入。该方法涉及训练一个较小的模型来模仿一个较大的预训练模型的行为。预训练模型生成“教师”预测结果,然后用于训练较小的“学生”模型。通过这样做,学生模型可以从较大模型的知识中学习,而无需存储所有参数。 - 适配器训练(
adapter training),它由 Houlsby 等人于 2019 年引入。适配器是添加到预训练模型中的小型神经网络,用于特定任务的微调。这些适配器只占原始模型大小的一小部分,这使得训练更快,内存需求更低。适配器可以针对多种任务进行训练,然后插入到预训练模型中以执行新任务。 - 渐进收缩(
progressive shrinking),它由 Kaplan 等人于 2020 年引入。这种技术涉及在 fine-tuning 期间逐渐减小预训练模型的大小。从一个大模型开始,逐渐减少参数的数量,直到达到所需的性能。这种方法可以产生比从头开始训练的模型性能更好的小型模型。
- 蒸馏(
- prompt-tuning
- 只修改模型的输入,不需要大量计算资源
参考:预训练大语言模型的三种微调技术总结:fine-tuning、parameter-efficient fine-tuning 和 prompt-tuning
Gemini #
谷歌官宣 Bard 更名 Gemini,是大模型也是产品,集聊天助手、搜索引擎于一身,将带来哪些影响?
Qwen #





Qwen 不仅仅是一个语言模型,而是一个致力于实现通用人工智能(AGI)的项目,目前包含了大型语言模型(LLM)和大型多模态模型(LMM)。下图展示了 Qwen 的主要组成部分:
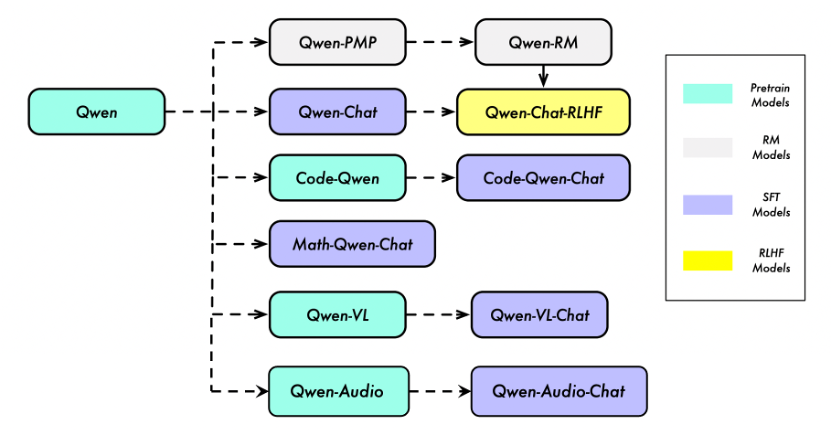
在这里,“Qwen” 指的是基础语言模型,而 “Qwen-Chat” 则指的是通过后训练技术如 SFT(有监督微调)和 RLHF(强化学习人类反馈)训练的聊天模型。
我们还有提供了专门针对特定领域和任务的模型,例如用于编程的 “Code-Qwen” 和用于数学的 “Math-Qwen”。
大型语言模型(LLM)可以通过模态对齐扩展到多模态,因此我们有视觉-语言模型 “Qwen-VL” 以及音频-语言模型 “Qwen-Audio” 。
- RLHF(
Reinforcement Learning from Human Feedback)
大模型,如 GPT(Generative Pretrained Transformer)或 BERT(Bidirectional Encoder Representations from Transformers),是基于变换器(Transformer)架构的深度学习模型。它们通常用于自然语言处理任务。让我来详细解释这些模型的工作过程:
- 接收 Prompt: 当模型接收到一段文本(称为“prompt”),它首先需要理解和处理这段文本。在处理前,通常会先进行分词(将句子分解成单词或子词单元)。
- 转换为嵌入 (
Embedding): 分词后,模型将每个词或子词转换为一个嵌入。嵌入是一种高维空间中的向量,这些向量捕捉了词的语义和语法属性。嵌入可以通过查找预训练的嵌入矩阵来获得,这个矩阵将每个词映射到一个固定长度的向量。- 嵌入(Embedding)是将词、短语或者整个文档从原始表示(通常是文本形式的)转换为实数向量的过程。在自然语言处理(NLP)中,嵌入向量通常捕捉单词的语义意义和在语境中的用法。这些嵌入向量让计算机能够理解词语,并对其进行数学运算。嵌入向量是深度学习模型能够处理文本数据的关键。
- 注意力计算和前馈计算:
之后,模型通过其多层结构进行计算,每一层都包含两个主要部分:
- 自注意力机制(
Self-Attention): 这个机制让模型能够在处理每个词时考虑到句子中的其他词,从而理解词与词之间的关系。 - 前馈网络(
Feed-Forward Neural Network): 在自注意力之后,每个词的表示将通过一个前馈网络,这个网络通常包含几个线性变换和非线性激活函数。
- 自注意力机制(
- 生成
Logits: 每一层的输出会传递到下一层,直到最后一层。在最后一层,模型生成一个 logit 向量,其长度等于词汇表的大小。每个 logit 代表模型预测下一个词是词汇表中每个词的非规范化概率。 - 概率分布: 最终,logits 通过一个激活函数(如 SoftMax)转换为概率分布。SoftMax 函数可以确保所有可能词的预测概率加起来等于 1。 这个概率分布反映了在给定前面的文本后,模型预测下一个词是词汇表中任何一个词的可能性。
- 生成文本: 根据这个概率分布,模型会选择概率最高的词作为下一个词,或者根据概率分布随机抽取一个词,从而生成文本。
整个过程涉及大量的矩阵计算,通常在 GPU 或 TPU 上执行以加速这些操作。这种模型的强大之处在于其能够理解和生成复杂的语言结构,这使得它们在许多自然语言任务中都非常有效。
嵌入 (Embedding) 是高维空间中的点,这些点代表了词汇表中的词。它们通常通过训练得到,以便具有这样的属性:语义或语法上相似的词在嵌入空间中彼此靠近。这里有一些关于嵌入的关键点:
维度: 嵌入向量有固定的维度,这个维度通常远小于词汇表的大小。例如,你可能有一个由数百万个词组成的词汇表,但每个词的嵌入向量可能只有几百维。
训练过程: 在预训练的模型(如 word2vec 或 GloVe)中,嵌入向量是通过在大量文本上学习得到的,这些模型会调整嵌入向量,使得在文本中共现的词在嵌入空间中更接近。
上下文敏感度: 传统的嵌入模型(如 word2vec 和 GloVe)生成的是静态嵌入,这意味着对于词汇表中的每个词,它总是有同样的嵌入向量,不管它出现在什么上下文中。而上下文相关的嵌入(如 BERT 中的嵌入)能够根据词出现的上下文生成不同的向量。
嵌入的使用: 嵌入向量用于初始化深度学习模型中的权重,随着模型在特定任务上的训练,它们可能会进行微调。例如,在 GPT 这样的模型中,嵌入层是模型的第一层,它将输入的文本转换为向量,这些向量随后通过模型的其它层进行处理。
举一个简单的比喻,你可以想象每个词都是一点颜料,而嵌入就像是把这些点颜料滴在一个巨大的白纸上。在这张白纸上,相似的颜色(词)会更接近,而不同的颜色(词)会更远。深度学习模型通过这样的方式“看”文本,并了解不同词和短语之间的关系。
“Logit”这个词来源于 logistic regression(逻辑回归)中,是“logistic unit”的缩写。在数学上,logit 函数通常指的是一个特定的函数,它把一个概率值(介于 0 和 1 之间的值)映射到负无穷到正无穷的范围内。这个函数是逻辑函数的逆函数。但在深度学习和机器学习的上下文中,“logit"一词有时被用来指代模型的原始输出,即还没有经过 softmax 或其他归一化函数转换成概率之前的值。
在深度学习中,当我们讨论模型(尤其是分类模型)的输出时,模型通常会输出一个向量,这个向量的每个元素对应于一个类别的得分或者说是“原始”概率——这就是 logit。这些得分后来通常会通过一个 softmax 函数转换成概率分布,softmax 函数能够确保所有输出值的总和为 1,使其可以被解释为概率。
叶王 © 2013-2024 版权所有。如果本文档对你有所帮助,可以请作者喝饮料。