Kubernetes 网络从零开始
一、计算机网络基础
自底向上
1. 物理层
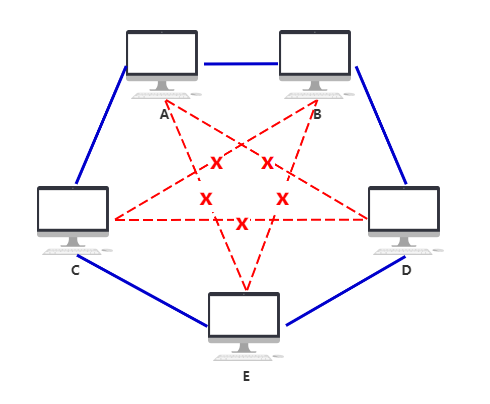
- 物理层负责把两台计算机连起来,
- 计算机之间通过高低电频来传送 0,1 这样的电信号。
集线器
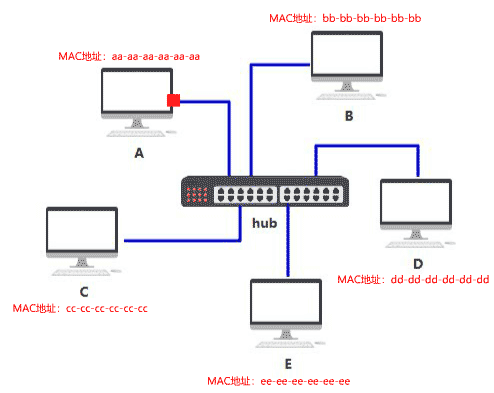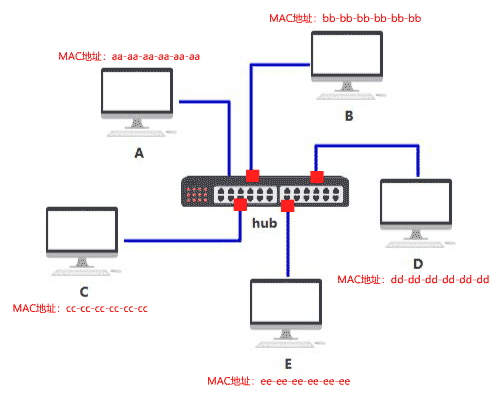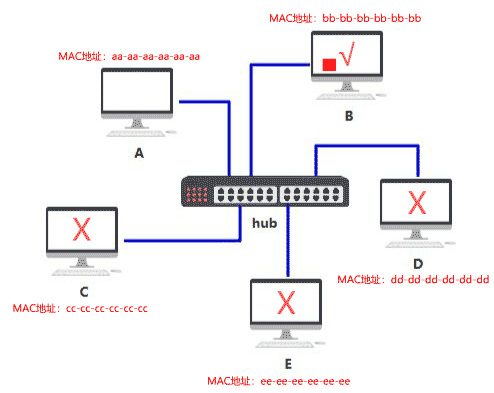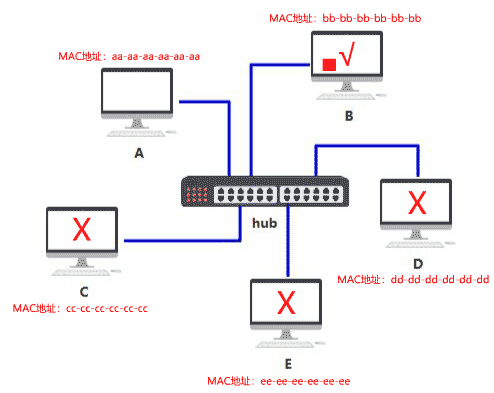
怎么知道数据包是不是发给自己的呢
2 数据链路层
只发给目标 MAC 地址指向的那台电脑
交换机 switch
switch 本身就是一种 bridge/网桥
3 网络层
如果机器数量超过了路由器的网口数量
路由器 1
- MAC 长度为 48 位
- 如:
00-16-EA-AE-3C-40 - 前 24 位(
00-16-EA)代表网络硬件制造商的编号 - 后 24 位(
AE-3C-40)是该厂家自己分配的系列号
- 如:
- 划分
子网 - 引入
IP 地址
路由器 2
| 目的地址 | 下一跳 | 端口 |
|---|---|---|
| 192.168.0.0/24 | 0 | |
| 192.168.0.254/32 | 0 | |
| 192.168.1.0/24 | 1 | |
| 192.168.1.254/32 | 1 | |
| 192.168.2.0/24 | 192.168.100.5 | |
| 192.168.100.0/24 | 2 | |
| 192.168.100.4/32 | 2 |
路由表是各种路由算法 + 人工配置逐步完善起来的
路由器 3
数据包的两个 IP 地址不变,MAC 地址不断变化
4 传输层 (TCP, UDP)
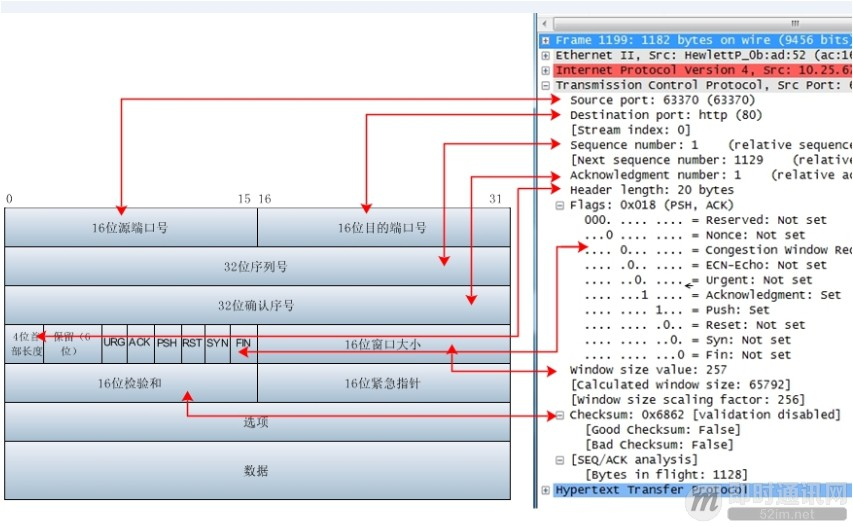
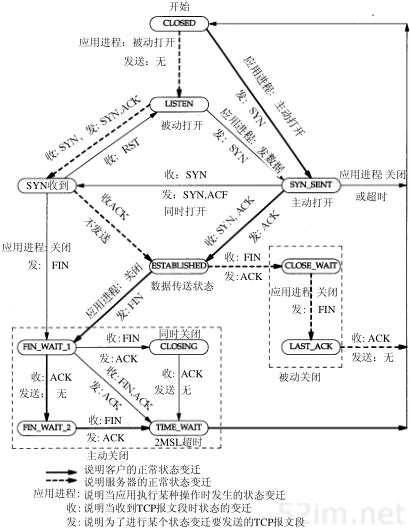
5 会话层, 6. 表示层
- 表示层、会话层的东西,更多的是做成了一种标准件,直接被拿来用,集成进了应用中。
- 比如说你要做一个视频聊天,你需要会话控制,实现拨号、呼叫、通话、暂停、挂断等,然后你拿来了 sip,这就是
会话层的东西; - 你需要视频的编码与压缩,把你这采集的视频信号传输到对面并播放,然后你拿来了 H.264,这个就是
表示层的东西。

5 会话层, 6. 表示层
会话层:为两端通信实体建立连接(会话),中间有认证鉴权以及检查点记录(供会话意外中断的时候可以继续,类似断点续传)。表示层:决定数据的展现(编码)形式,如同一部电影可以采样、量化、编码为 RMVB、AVI,一张图片能够是 JPEG、BMP、PNG 等。

7 应用层
应用层:就是应用软件使用的协议,如邮箱使用的 POP3,SMTP、远程登录使用的 Telnet、获取 IP 地址的 DHCP、域名解析的 DNS、网页浏览的 http 协议等;这部分协议主要是规定应用软件如何去进行通信的。

8 有趣的问题 🤔
- MAC 地址可以修改吗?
- 有了 MAC 地址为什么还需要 IP?
- 可以没有 MAC 地址吗?
- 交换机既然可以学习 MAC 地址,那就一定可以学习 IP 地址。这样,每个网口所连电脑的 IP 映射关系也就知道了。
- 电脑 A 如果想给 C 发数据,可以不查 C 的 MAC 地址,而是直接给交换机发一个 IP 报文(注意,这次没有 MAC 帧)。交换机收到后直接转发给电脑 C。整个过程就仿佛回到了最开始的点对点链接路。
- 现在没有去掉 MAC 地址,可能是因为以太网设备已经遍布全球,也足够便宜,已经没有必要再优化了。
二、容器网络
2.1 隔离
Linux Namespaces
- Mount:隔离文件系统加载点;
- UTS:隔离主机名和域名;
- IPC:隔离跨进程通信(IPC)资源;
- PID:隔离 PID 空间;
- 网络:隔离网络接口;
- 用户:隔离 UID/GID 空间;
- Cgroup:隔离 cgroup 根目录。
namespace 问题
- 基于 Linux Namespace 的隔离机制相比于虚拟化技术也有很多不足之处,其中最主要的问题就是:
隔离得不彻底 - 容器只是运行在宿主机上的一种
特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核- 要在 Windows 宿主机上运行 Linux 容器,或者在低版本的 Linux 宿主机上运行高版本的 Linux 容器,都是行不通的
- 在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,最典型的例子就是:
时间- 容器中的程序使用 settimeofday(2) 系统调用修改了时间,整个宿主机的时间都会被随之修改
限制:Linux Cgroups
- Linux Cgroups 的全称是 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等
Docker network namespace
- ns 保存目录一般是
/var/run/docker/netns/非默认的/var/run/netns/路径- 所以
ip netns list没有 docker 创建的 ns
2.2 通信
跨 net ns 通信:veth pair
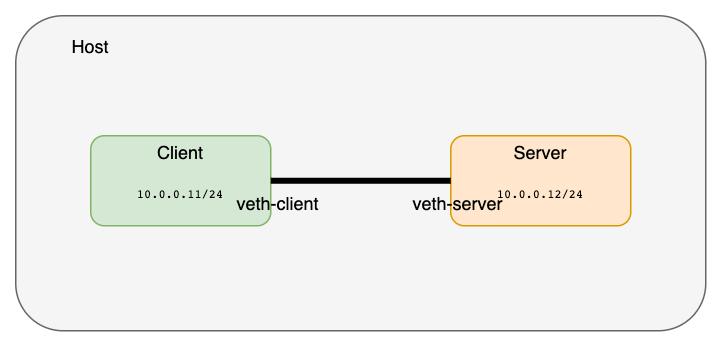
- veth 是
虚拟以太网卡(Virtual Ethernet)的缩写 - veth 设备总是成对的
- veth pair 一端发送的数据会在另外一端接收,非常像 Linux 的
双向管道
单机容器通信:网桥

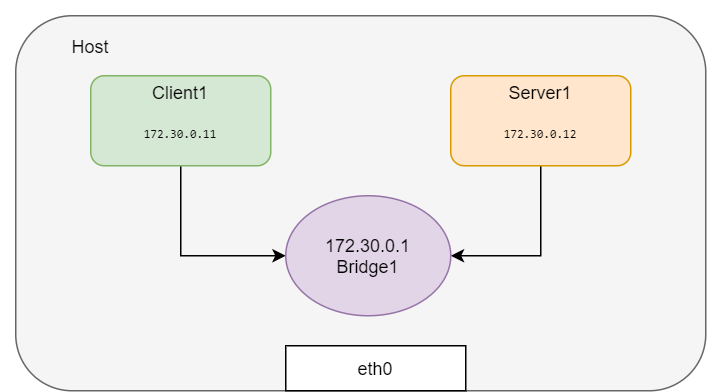
- 不同
net ns如何互通? - 通过两个接口连接两个
冲突域的装置称为网桥 - 网桥的作用相当于 OSI 模型中的
数据链路层
跨主机通信
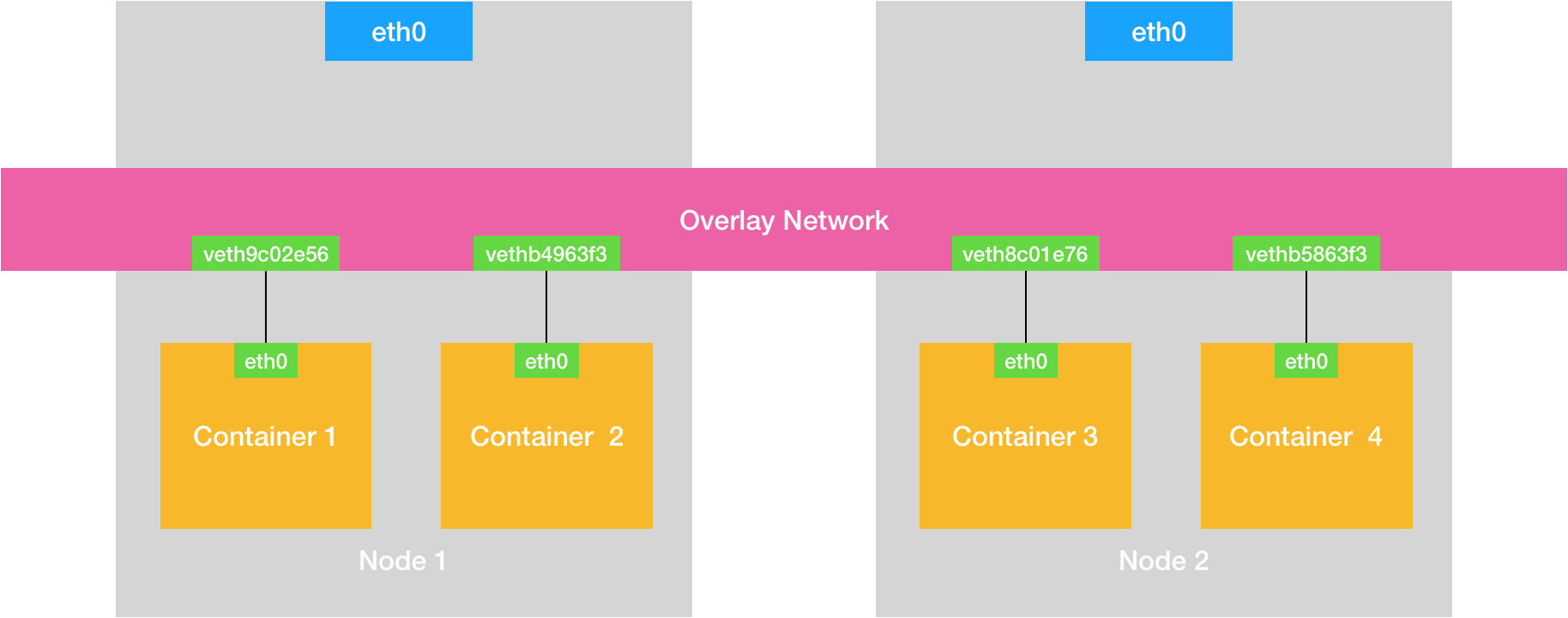
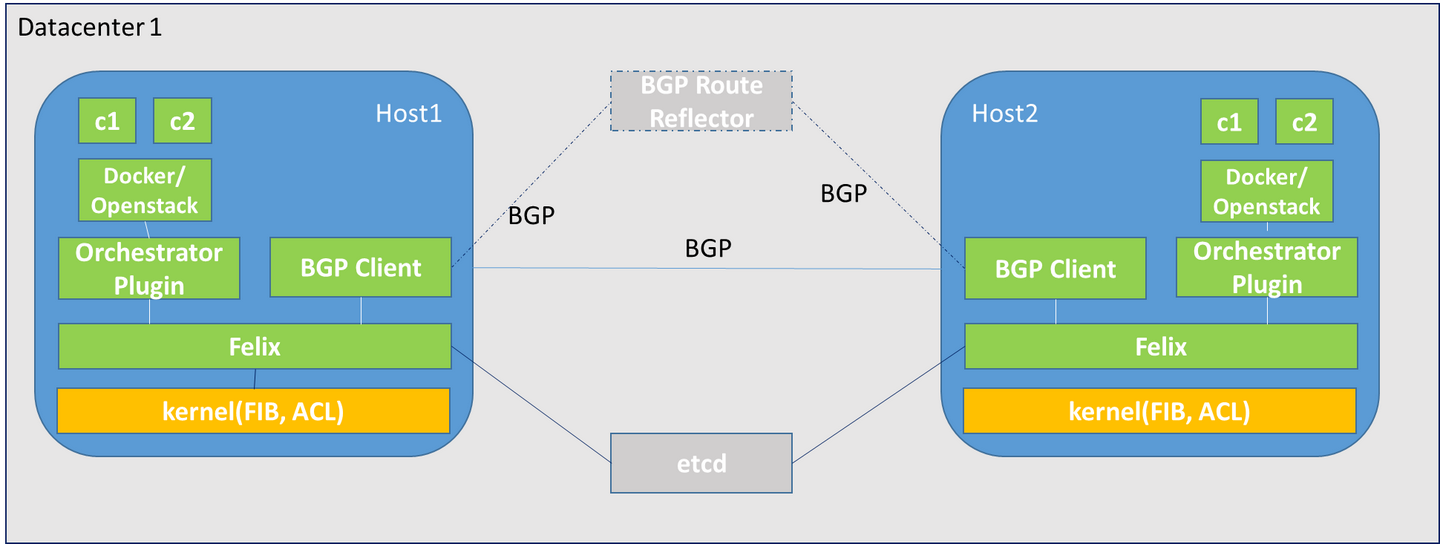
NAT:利用宿主机的 IP 和 iptables 来达到容器与主机之间的通信Tunnel(overlay):通过软件构建一个覆盖在已有宿主机网络之上的,可以把所有容器连通在一起的虚拟网络Routing:通过路由配置的方式让容器对容器,容器对宿主机之间相通信
tun/tap 设备
- 从 Linux 文件系统的角度看,是用户可以用文件句柄操作的
字符设备 - 从网络虚拟化角度看,是
虚拟网卡,一端连着网络协议栈,另一端连着用户态程序网络栈主要包括:网卡(Network Interface)、回环设备(Loopback Device)、路由表(Routing Table),iptables 规则和 DNS 配置等
tun/tap可以将 TCP/IP 协议栈处理好的网络包发送给任何一个使用 tun/tap 驱动的进程,由进程处理后发到物理链路中- tun/tap 像是用户程序空间的
钩子,可以很方便地将对网络包的处理程序挂在这个钩子上,OpenVPN、Vtun、flannel 都是基于它实现隧道包封装的。
- tun/tap 像是用户程序空间的
tun/tap 原理
tun虚拟的是点对点设备- tun 设备的
/dev/tunX文件收发的是 IP 包,因此只能工作在 L3
- tun 设备的
tap虚拟的是以太网设备- tap 设备的
/dev/tapX文件收发的是链路层数据包,可以与物理网卡做桥接
- tap 设备的
- 对 tun/tap 设备而言,它与物理网卡的不同表现在它的数据源不是物理链路,而是来自
用户态
Flannel
Flannel 项目是 CoreOS 公司主推的容器网络方案。
Flannel 项目本身只是一个框架,真正为我们提供容器网络功能的,是 Flannel 的后端实现,分别是:
UDP(最早实现,性能最差,弃用)- Flannel 之所以最先选择 UDP 模式,就是因为这种模式是最直接、也是最容易理解的容器跨主网络实现
- VXLAN
- host-gw
Flannel UDP 方案
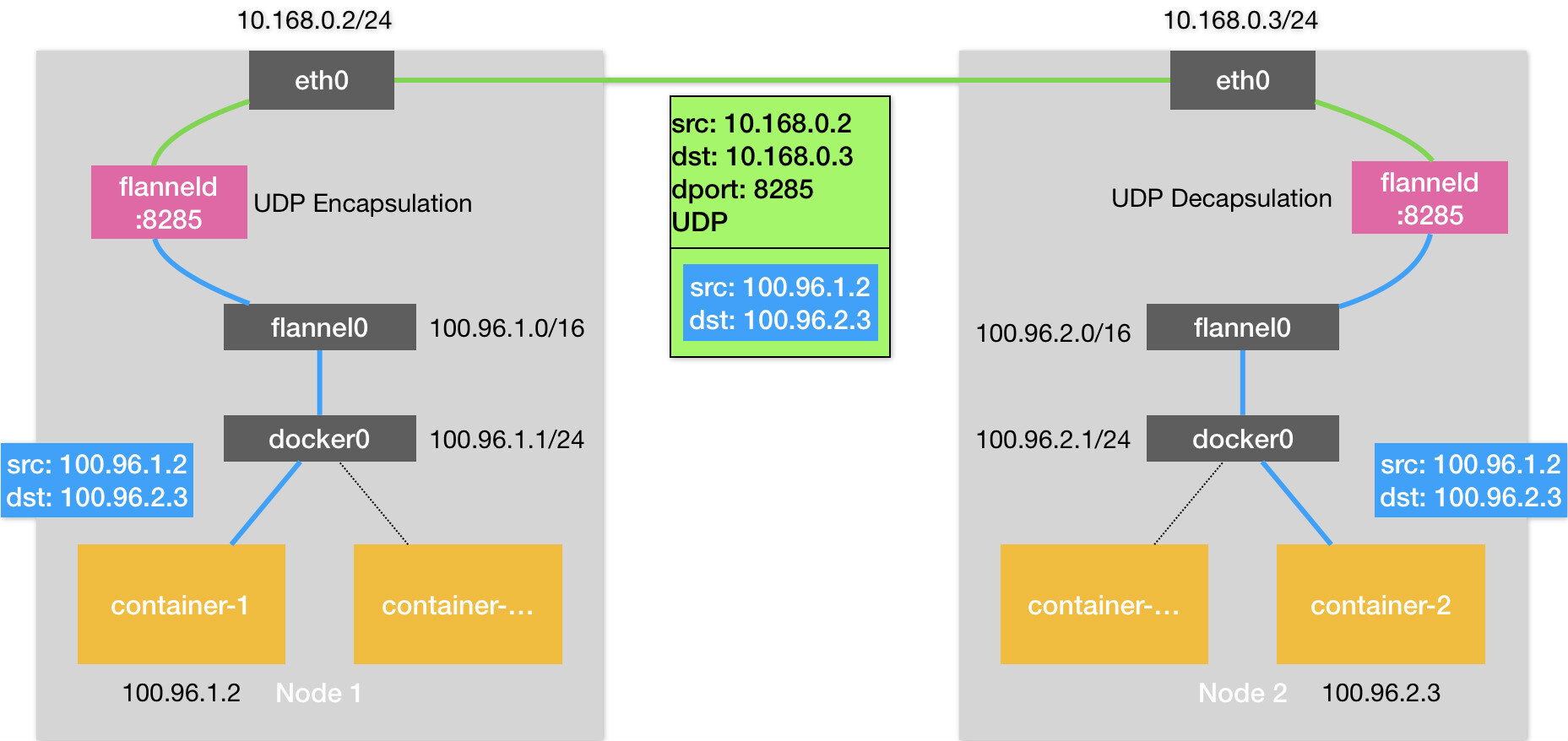
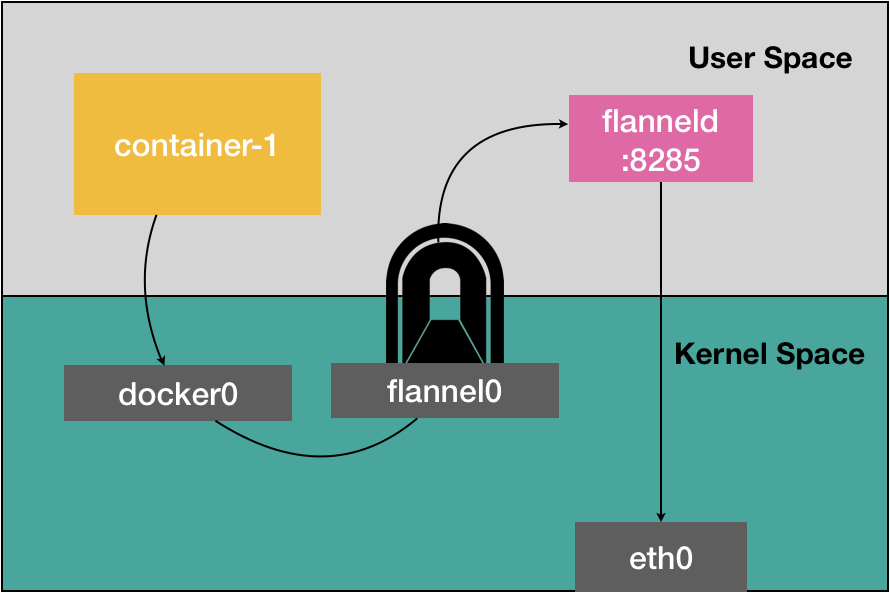
# Node 1
$ ip route
# 最长匹配原则
default via 10.168.0.1 dev eth0
100.96.0.0/16 dev flannel0 proto kernel scope link src 100.96.1.0
100.96.1.0/24 dev docker0 proto kernel scope link src 100.96.1.1
10.168.0.0/24 dev eth0 proto kernel scope link src 10.168.0.2
# Node 2
$ ip route
default via 10.168.0.1 dev eth0
100.96.0.0/16 dev flannel0 proto kernel scope link src 100.96.2.0
100.96.2.0/24 dev docker0 proto kernel scope link src 100.96.2.1
10.168.0.0/24 dev eth0 proto kernel scope link src 10.168.0.3
$ etcdctl ls
/coreos.com/network/subnets
/coreos.com/network/subnets/100.96.1.0-24
/coreos.com/network/subnets/100.96.2.0-24
/coreos.com/network/subnets/100.96.3.0-24
$ etcdctl get /coreos.com/network/subnets/100.96.2.0-24
{"PublicIP":"10.168.0.3"}
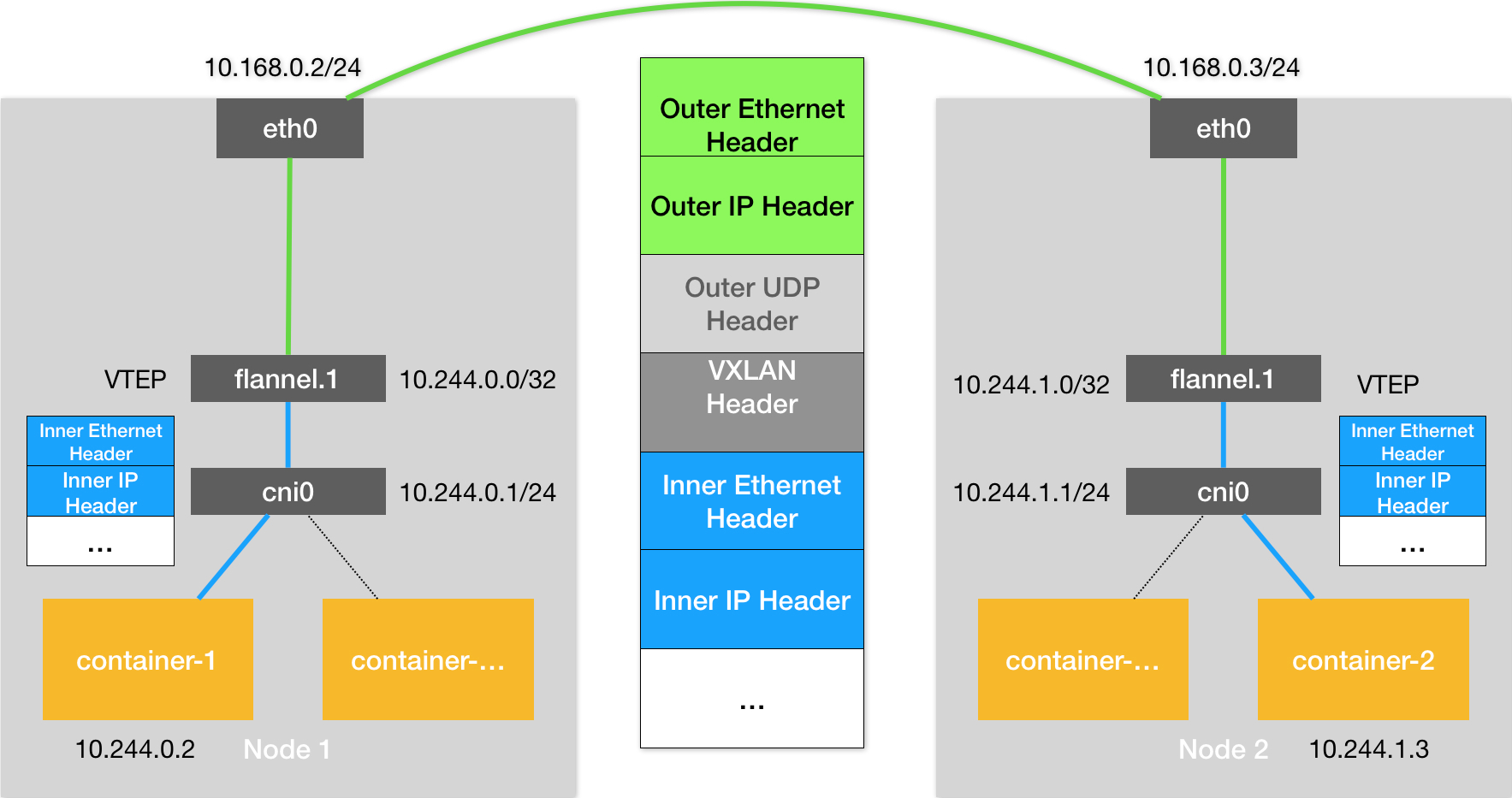
Flannel VXLAN
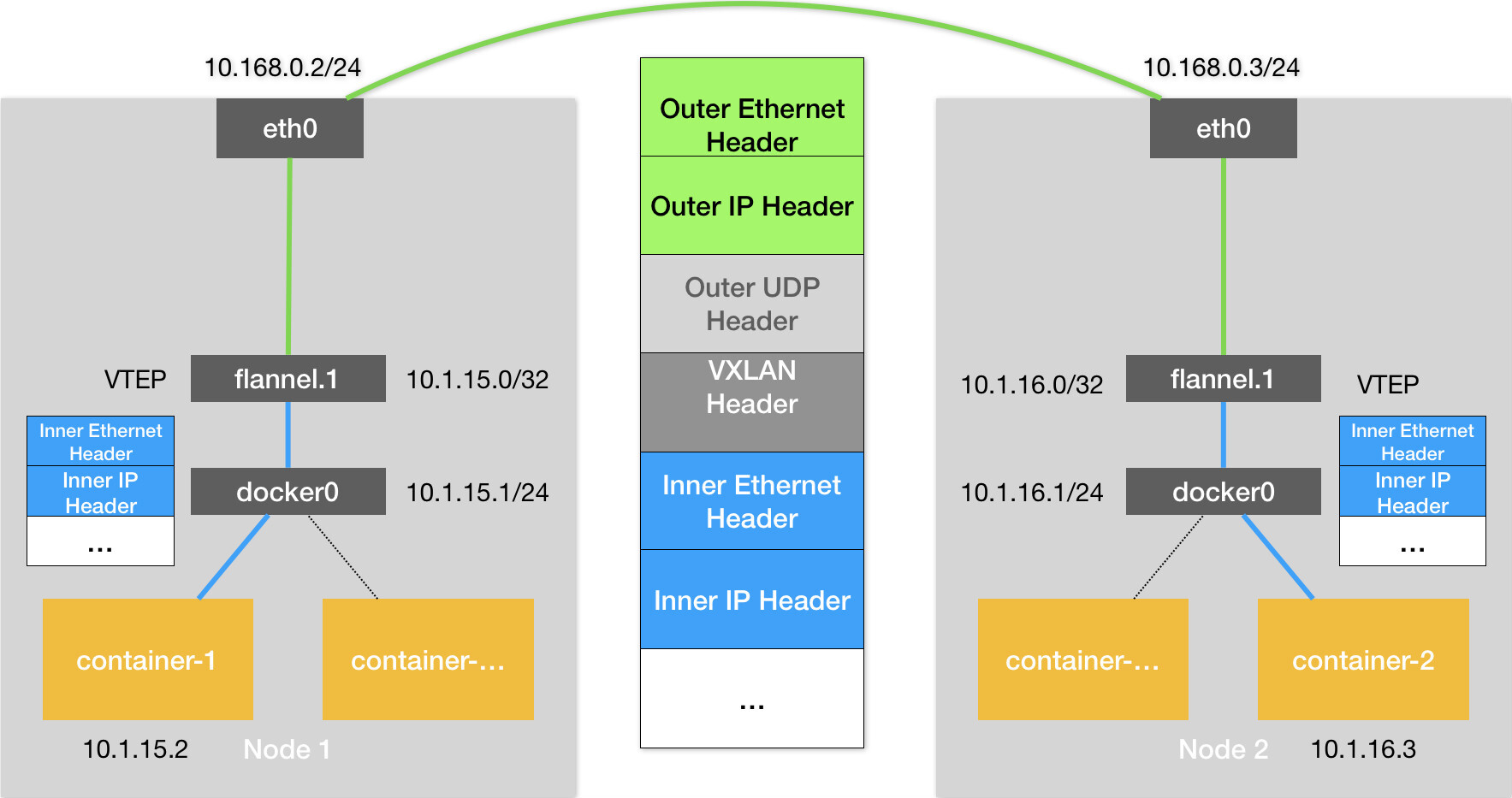
VXLAN:即 Virtual Extensible LAN,是 Linux内核本身就支持的一种网络虚似化技术VTEP: VXLAN Tunnel End Point
# 在 Node 1上
$ route -n
10.1.16.0 10.1.16.0 255.255.255.0 UG 0 0 0 flannel.1
$ ip neigh show dev flannel.1
10.1.16.0 lladdr 5e:f8:4f:00:e3:37 PERMANENT
# flannel.1 “网桥” 对应的 FDB 信息,找到目标宿主机 IP
$ bridge fdb show flannel.1 | grep 5e:f8:4f:00:e3:37
5e:f8:4f:00:e3:37 dev flannel.1 dst 10.168.0.3 self permanent
Flannel host-gw
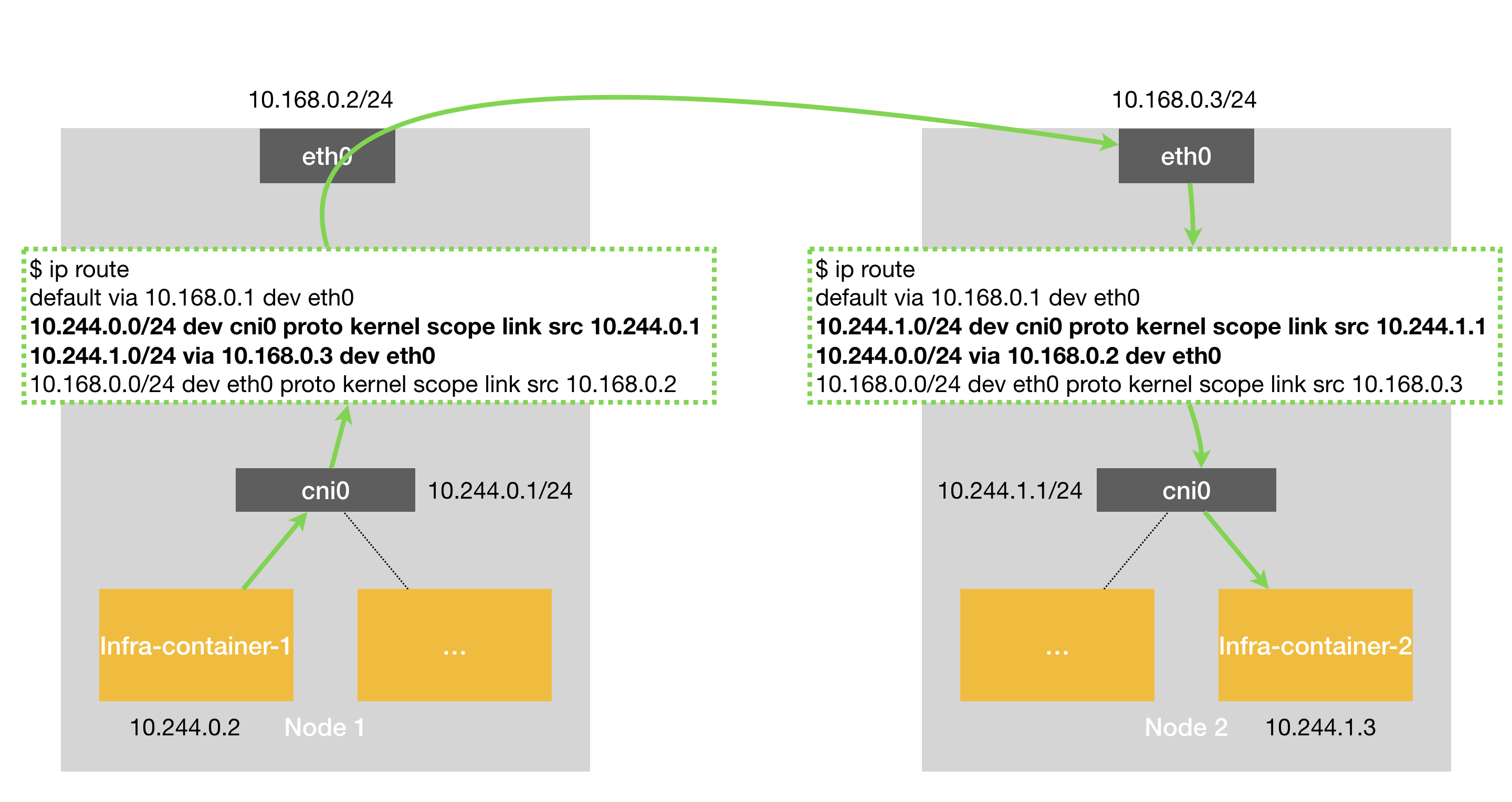
# node1
$ ip route
10.244.1.0/24 via 10.168.0.3 dev eth0
- 主机会充当这条容器通信路径里的网关,这也正是
host-gw的含义 - 通过 Etcd 和宿主机上的 flanneld 来维护路由信息
- 要求集群宿主机之间是
二层连通的
Calico
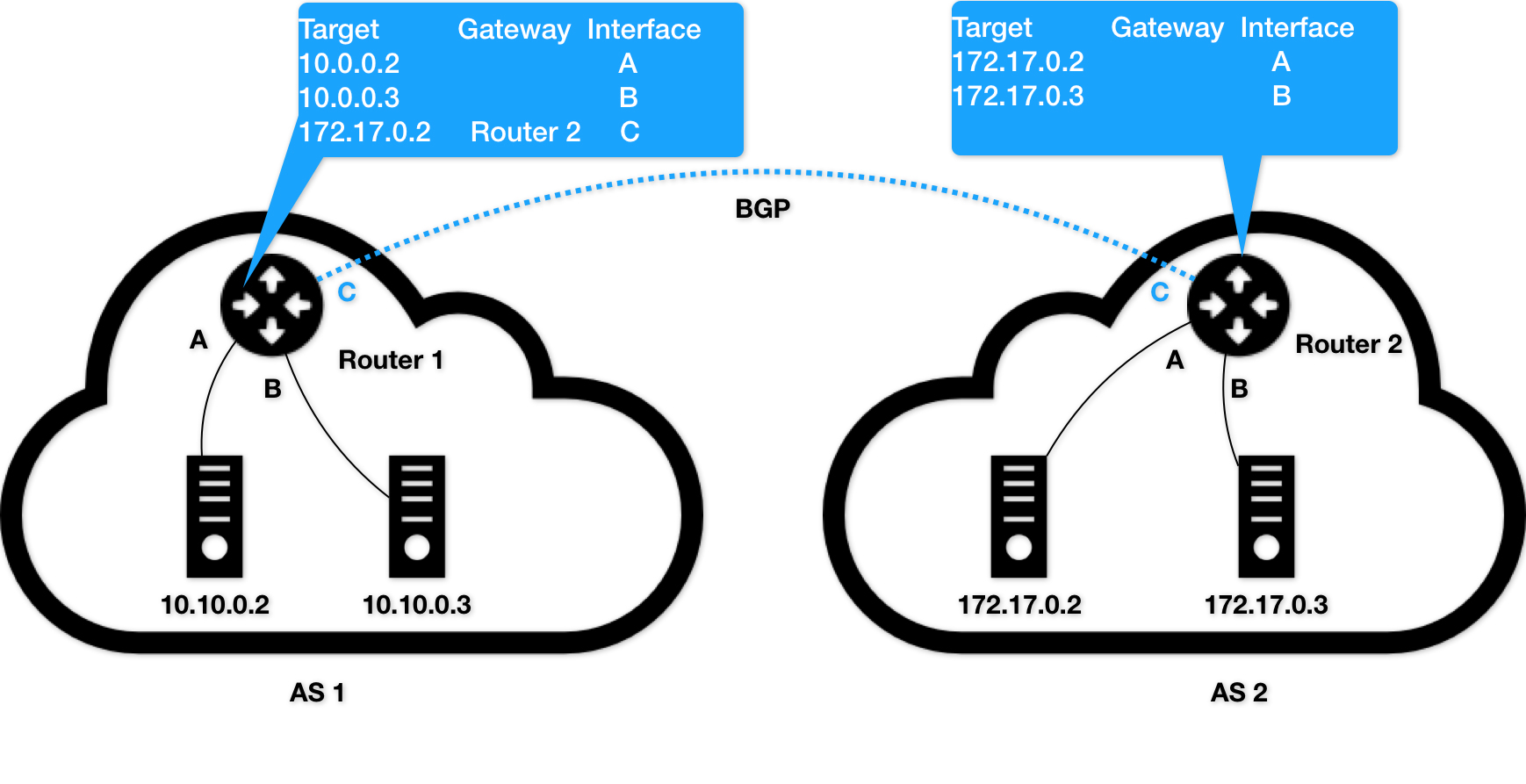
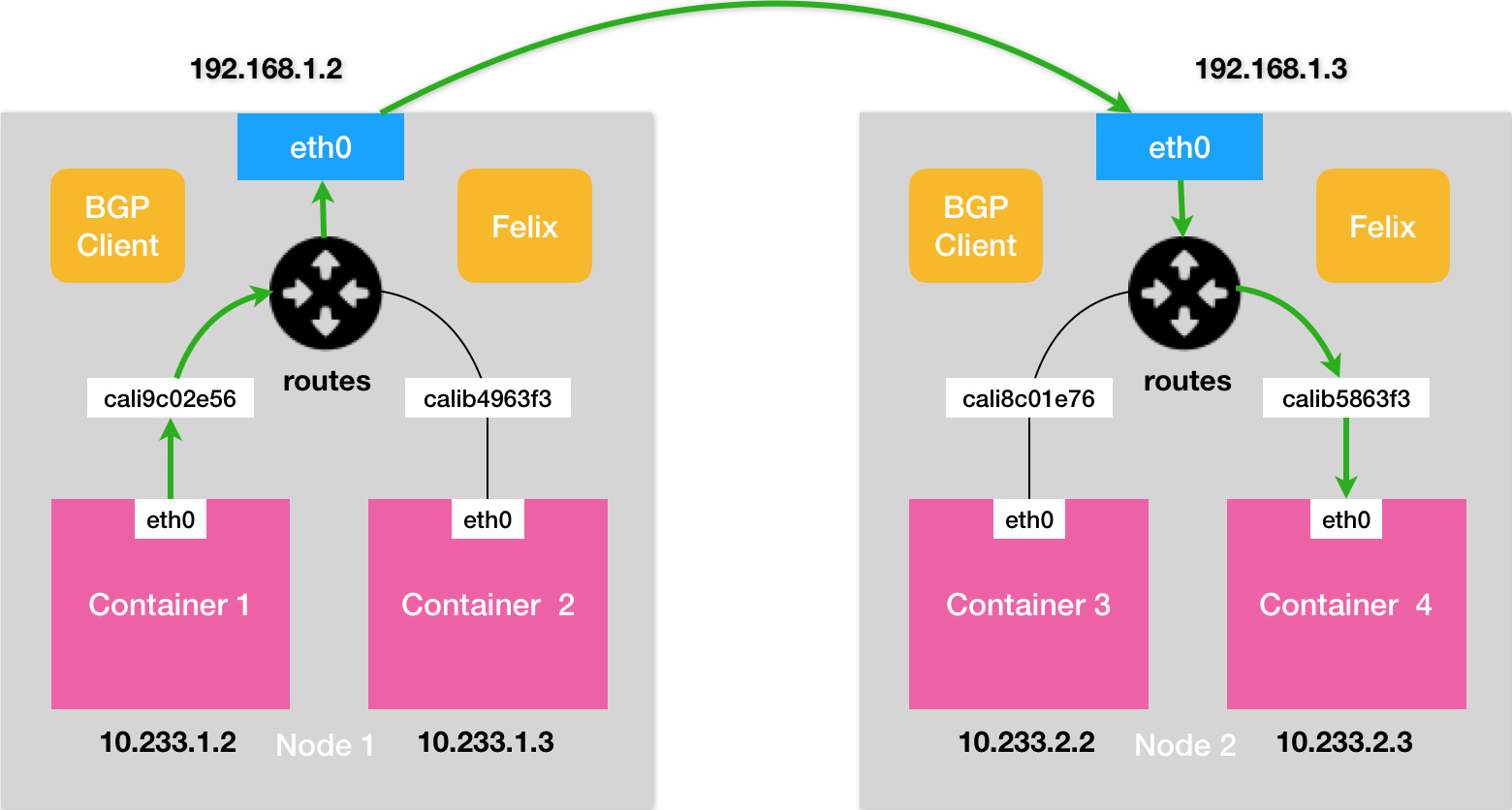
- 边界网关:路由表里拥有其他自治系统里的主机路由信息
- Calico
不会在宿主机上创建任何网桥设备
# node 2
10.233.2.3 dev cali5863f3 scope link
Calico IPIP 模式
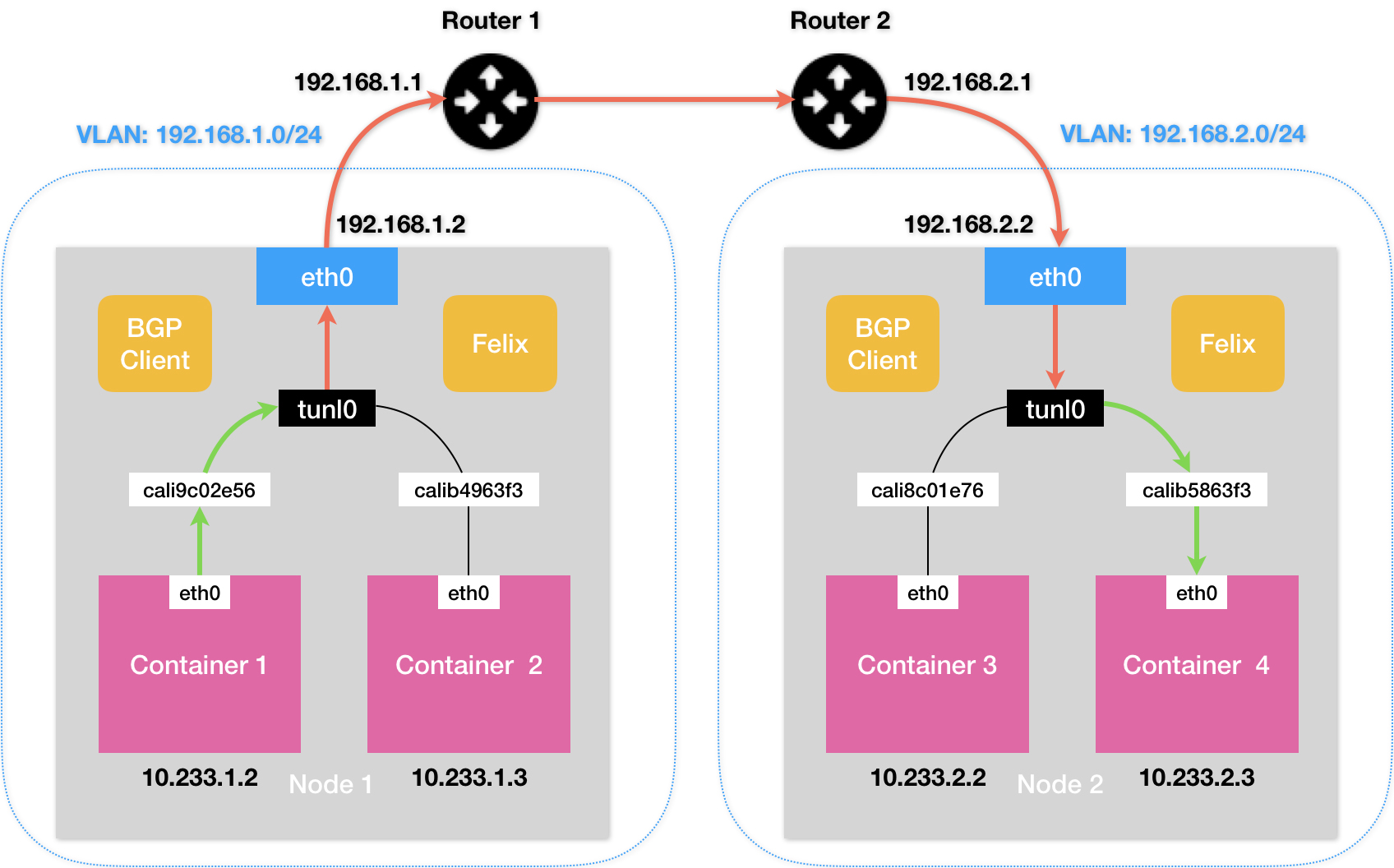
# node 1
10.233.2.0/24 via 192.168.2.2 tunl0
- Calico IPIP 模式与 Flannel VXLAN 模式的性能大致相当
- 公有云环境下,宿主机之间的网关,肯定不会允许用户进行干预和设置
- 在私有部署的环境下,想办法将宿主机网关也加入到 BGP Mesh 里从而避免使用 IPIP
三、Kubernetes 网络
CNI
CNI 网桥,它在宿主机上的设备名称默认是:cni0
# 子网范围可以在部署时配置
# 部署完成后,可以修改 kube-controller-manager 的配置文件来指定
$ kubeadm init --pod-network-cidr=10.244.0.0/16
网络方案:创建和配置 flannel.1 设备、配置宿主机路由、配置 ARP 和 FDB 表里的信息CNI 插件:配置 Infra 容器里面的网络栈,并把它连接到 CNI 网桥
pod 网络

这个其实前面都讲过了
service (负载均衡)
- Service 是由 kube-proxy 组件,加上 iptables 来共同实现的
iptables 5x5
| 规则名称 | mangle | nat(DNAT) | nat(SNAT) | filter | ||
|---|---|---|---|---|---|---|
| PREROUTING | ✓ | ✓ | ✓ | |||
| INPUT | ✓ | ✓ | ✓ | ✓ | ||
| OUTPUT | ✓ | ✓ | ✓ | ✓ | ✓ | |
| FORWARD | ✓ | ✓ | ✓ | |||
| POSTROUTING | ✓ | ✓ |
- 重点是
3 表 5 链,raw 和 security 比较少用 - iptables
不支持用户自定义表 - iptables 支持用户自定义链
iptables 5 链 (钩子位置)

iptables 底层实现是 netfilter,IP 层的 5 个 hook 的位置,对应 iptables 就是 5 条内置链
PREROUTING:DNAT(内部服务对外发布)INPUT:处理输入本地进程的包OUTPUT:处理本地进程的输出包FORWARD:处理转发的包POSTROUTING:SNAT(内部共享 IP 访问外部)
iptables 5 表 (分类管理 rule)
优先级从高到低分别是:raw、mangle、nat、filter、security
raw:iptables 是有状态的,即 iptables 对数据包有连接追踪(connectiontracking)机制,而 raw 是用来去除这种追踪机制的;mangle:修改数据包的服务类型,生存周期,为数据包设置标记,实现流量整形、策略路由;nat:用于修改数据包的源和目的地址;filter:用于控制到达某条链上的数据包是继续放行、直接丢弃(drop)或拒绝(reject);security:最不常用的表(通常,我们说 iptables 只有 4 张表,security`是新加入的特性),用于在数据包上应用 SELinux。
iptables rule
一条 iptables 规则包含:匹配条件(多个条件是逻辑与的关系)和动作
DROP:直接将数据包丢弃,不再进行后续的处理。可以用来模拟宕机REJECT:给客户端返回 Connection Refused 或 Destination Unreachable 报文RETURN:跳出当前链,该链里后续的规则不再执行ACCEPT:同意数据包通过,继续执行后续的规则QUEUE:将数据包放入用户空间的队列,供用户空间的程序处理JUMP:跳转到其他用户自定义的链继续执行
iptables 命令示例
iptables [-t 表名] 管理选项 [链名] [匹配条件] [-j 控制类型]
# 查询规则 (默认是 filter 表)
iptables -L -n
# 查询 nat 表的规则
iptables -t nat -L -n
# 只开启 22 端口
iptables -A INPUT -p tcp --dport 22 -j ACCEPT
# 关闭所有外部访问
iptables -P INPUT DROP
# 允许本机访问
iptables -A INPUT -i lo -j ACCEPT
# 允许访问外网
iptables -A INPUT -m state --state ESTABLISHED -j ACCEPT
# 80 端口被占了,实际 Web 服务监听在 8080 端口上
iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 8080
iptables -A INPUT -p icmp -j DROP
service - iptables 模式
$ kubectl get endpoints hostnames
NAME ENDPOINTS
hostnames 10.244.1.7:9376,10.244.2.3:9376,10.244.3.6:9376
$ kubectl get svc hostnames
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hostnames ClusterIP 10.0.1.175 <none> 80/TCP 5s
# iptables
-A KUBE-SERVICES -d 10.0.1.175/32 -p tcp -m comment --comment "default/hostnames: cluster IP" -m tcp --dport 80 -j KUBE-SVC-NWV5X2332I4OT4T3
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-WNBA2IHDGP2BOBGZ
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-X3P2623AGDH6CDF3
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -j KUBE-SEP-57KPRZ3JQVENLNBR
-A KUBE-SEP-57KPRZ3JQVENLNBR -d 10.244.3.6/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-57KPRZ3JQVENLNBR -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.3.6:9376
-A KUBE-SEP-WNBA2IHDGP2BOBGZ -d 10.244.1.7/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-WNBA2IHDGP2BOBGZ -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.1.7:9376
-A KUBE-SEP-X3P2623AGDH6CDF3 -d 10.244.2.3/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-X3P2623AGDH6CDF3 -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.2.3:9376
service - ipvs 模式
IPVS 在内核中的实现其实也是基于 Netfilter 的 NAT 模式
$ ip addr
73:kube-ipvs0:<BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 1a:ce:f5:5f:c1:4d brd ff:ff:ff:ff:ff:ff
inet 10.0.1.175/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
$ ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.102.128.4:80 rr
-> 10.244.3.6:9376 Masq 1 0 0
-> 10.244.1.7:9376 Masq 1 0 0
-> 10.244.2.3:9376 Masq 1 0 0
集群外访问
- NodePort
- LoadBalancer
- ExternalName
# iptables
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/my-nginx: nodePort" -m tcp --dport 8080 -j KUBE-SVC-67RL4FN6JRUPOJYM
# IP 包离开宿主机发往目的 Pod 时进行 SNAT。将这个 IP 包的源地址替换成了这台宿主机上的 CNI 网桥地址,或者宿主机本身的 IP 地址(如果 CNI 网桥不存在的话)
# 查看该 IP 包是否有一个 “0x4000” 的标志(IP 包被执行 DNAT 操作之前被打上去的)
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE
client
\ ^
\ \
v \
node 1 <--- node 2
| ^ SNAT
| | --->
v |
endpoint
kube-dns/coredns

nameserver 10.250.0.10
search default.svc.cluster.local svc.cluster.local cluster.local
# 如果需要 lookup 的 Domain 中包含少于 5 个 `.` ,那么将会被当做非绝对域名
options ndots:5
$ curl a
a.default.svc.cluster.local # Found
$ curl a.default
a.default.default.svc.cluster.local # Not Found
a.default.svc.cluster.local # Found
# 在要访问的域名后面加上点(.),可以避免走 search 域进行匹配
$ curl iftech.io.
默认ClusterFirst,优先使用 kubedns 进行域名解析,解析不成功才会使用宿主机的 DNS 配置进行解析
Ingress
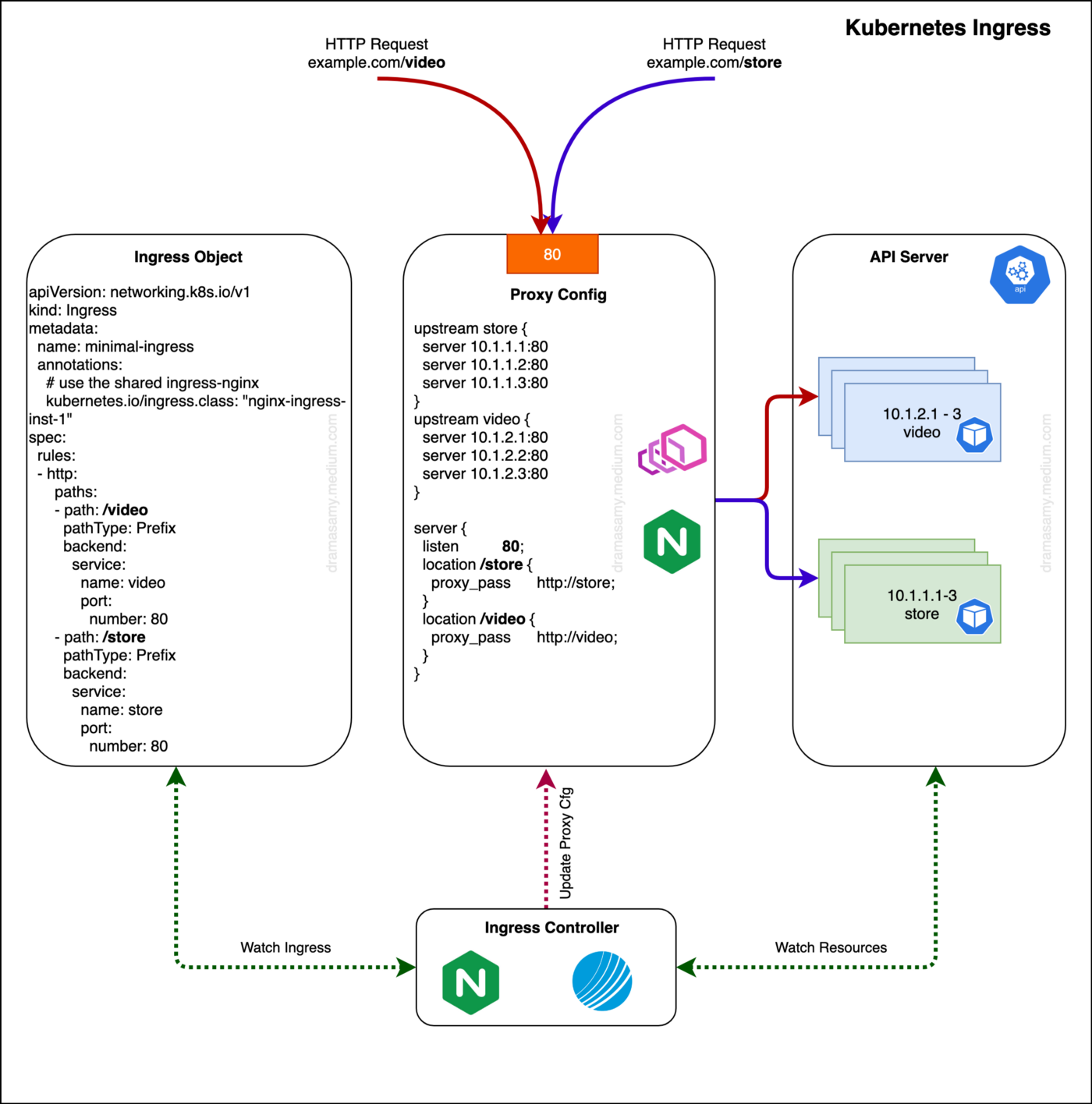
- 所谓 Ingress,就是
Service 的 “Service”
常见网络问题排查
# 1. service 不通。区分 coredns 还是 service 问题
$ nslookup kubernetes.default
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
# 2. 查看 dns 实例
kubectl get pods --namespace=kube-system -l k8s-app=kube-dns
NAME READY STATUS RESTARTS AGE
coredns-7b96bf9f76-5hsxb 1/1 Running 0 1h
coredns-7b96bf9f76-mvmmt 1/1 Running 0 1h
# 3. service clusterIP 不通。查看 endpoints 问题还是 kube-proxy 问题
$ kubectl get endpoints hostnames
NAME ENDPOINTS
hostnames 10.244.0.5:9376,10.244.0.6:9376,10.244.0.7:9376
推荐书籍




