NCCL#
NCCL 在网络模型训练框架中位于深度学习框架(如 Torch、TF、PP 等),和 CUDA 框架之间。同级并列的还有深度学习库 CUDNN、线性代数库 CUBLAS。
Nvidia Collective multi-GPU Communication Library
是一个实现多 GPU 的 collective communication 通信(all-gather, reduce, broadcast)库,Nvidia 做了很多优化,以在 PCIe、Nvlink、InfiniBand 上实现较高的通信速度。
- PCIe 适用于标准 GPU 连接和一般数据传输
- NVLink 主要用于连接高性能计算(HPC)和深度学习应用中的 GPU,可以显著提高多 GPU 系统的数据传输和处理能力
- NVLink 可以提供每秒几百 GB 的带宽,显著高于 PCIe
GPU Direct P2P是一种允许 NVIDIA GPU 直接通过 PCIe 或 NVLink 互相通信的技术,无需 CPU 介入- InfiniBand 连接不同计算机或服务器的一种网络技术
Communication Primitive#
并行任务的通信一般可以分为
Point-to-point Communication- P2P 通信这种模式只有一个 sender 和一个 receiver,实现起来比较简单
Collective Communication- Collective Communication 包含多个 sender 多个 receiver
- 一般的通信原语包括 broadcast, gather, all-gather, scatter, reduce, all-reduce, reduce-scatter, all-to-all 等
ring-based Collective communication#
传统
Collective communication假设通信节点组成的 topology 是一颗 fat tree,这样通信效率最高- 但实际的通信 topology 可能比较复杂,并不是一个 fat tree
因此一般用
ring-based Collective communicationring-based Collective communication将所有的通信节点通过首尾连接形成一个单向环,数据在环上依次传输- 把要传输的数据分成 S 份,每次只传 N/S 的数据量,GPU1 接收到 GPU0 的一份数据后,也接着传到环的下个节点
- 时间为 S*(N/S/B) + (k-2)*(N/S/B) = N(S+K-2)/(SB) –> N/B,条件是 S 远大于 K,即数据的份数大于节点数,这个很容易满足
- 所以通信时间不随节点数的增加而增加,只和数据总量以及带宽有关
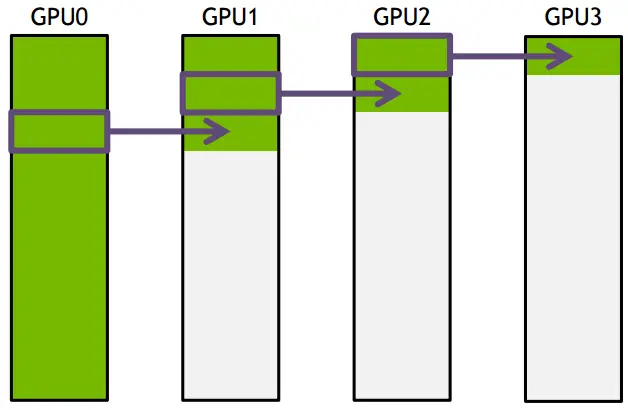
构建通信环的方式:
单机 4 卡
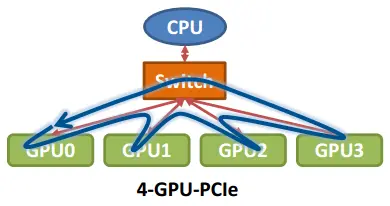
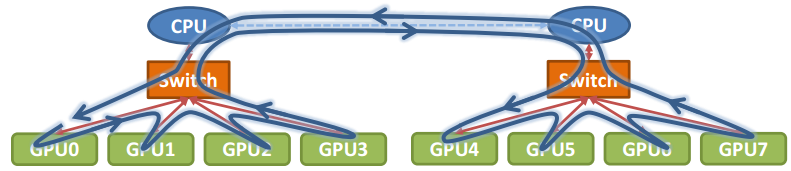
单机 8 卡
NCCL 实现#
NCCL 实现成 CUDA C++ kernels,包含 3 种 primitive operations:
- Copy
- Reduce
- ReduceAndCopy
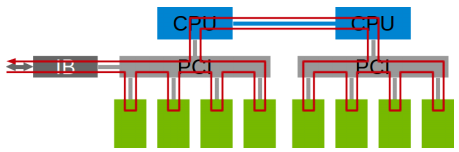
- NCCL 1.0 版本只支持单机多卡,卡之间通过 PCIe、NVlink、GPU Direct P2P 来通信。
- NCCL 2.0 会支持多机多卡,多机间通过 Sockets (Ethernet)或者 InfiniBand with GPU Direct RDMA 通信
参考:
叶王 © 2013-2026 版权所有。如果本文档对你有所帮助,可以请作者喝饮料。