CUDA#
Compute Unified Device Architecture- 统一计算架构
nvcc -V 显示的当前安装的 cuda 版本
- nvcc:
NVIDIA (R) Cuda compiler driver
- nvcc:
我们常说的 cuda 指的是
nvidia cuda toolkit软件开发包,而不是 GPU 驱动- cuda 版本也即 CUDA 工具包的版本,而不是显卡驱动版本
cuda 每个版本都对应一个最低版本的显卡驱动程序
cuda 程序是向后兼容的,针对特定版本的 CUDA 编译的应用程序将继续在后续驱动程序版本上工作
- cuda 可以是旧的,驱动可以是更新的
- 最新 nvidia 驱动版本支持所有版本的 CUDA
GPU 核心和 CUDA 核心通常指的是同一个概念。在 NVIDIA 的术语中,CUDA 核心是 GPU 上的处理单元,负责执行计算任务。
只有一半的 CUDA 能支持整数计算

- 在 CUDA 核心(
CUDA Core)的右边,是 TenSor 核心 (Tensor Core)- Tensor Cores 是 NVIDIA 在其 Volta 和后续架构中引入的另一种专用计算核心,主要用于加速深度学习和机器学习中的张量运算

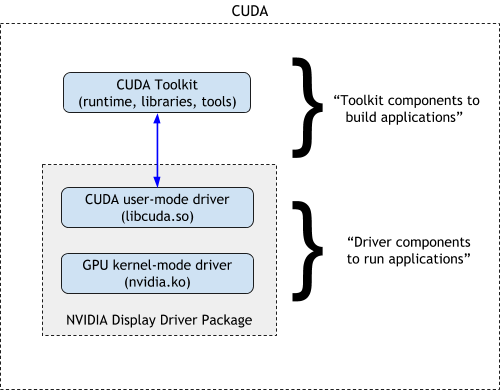
nvidia driver 和 cuda toolkit 版本兼容性#
- CUDA Toolkit
- runtime, libraries, tools
- Nvidia Display Driver Package
- CUDA user-mode driver (libcuda.so)
- GPU kernel-mode driver (nvidia.ko)
cuda-compat-XX 是干什么的?#
- 让 “新 CUDA Toolkit 编译的程序” 可以在 “老 driver” 上跑
- 永远优先升级 driver,只有在 driver 升不了、又要跑新 CUDA 程序时,才考虑 cuda-compat
下面这张表,说明的是:在某个 driver 版本下,是否 “需要 / 允许 / 有意义” 安装某个 cuda-compat-XX
| CUDA forwardcompatibility package | NVIDIA driver | |||||
|---|---|---|---|---|---|---|
| 535+ (CUDA 12.2) | 550+ (CUDA 12.4) | 570+ (CUDA 12.8) | 575+ (CUDA 12.9) | 580+ (CUDA 13.0) | 590+ (CUDA 13.1) | |
| cuda-compat-13-1 | C | C | C | C | C | N/A |
| cuda-compat-13-0 | C | C | C | C | N/A | X |
| cuda-compat-12-9 | C | C | C | N/A | X | X |
| cuda-compat-12-8 | C | C | N/A | X | X | X |
| cuda-compat-12-6 | C | C | X | X | X | X |
| cuda-compat-12-5 | C | C | X | X | X | X |
| cuda-compat-12-4 | C | N/A | X | X | X | X |
| cuda-compat-12-3 | C | X | X | X | X | X |
| cuda-compat-12-2 | N/A | X | X | X | X | X |
- C - Compatible
- X - Not compatible
- Branches not listed in the table above are end of life and are not supported targets for compatibility.
- New Feature Branches are not supported targets for CUDA Forward Compatibility.
Minor Version Compatibility#
从 CUDA 11 起,默认启用 “Minor Version Compatibility(MVC)”
不再像 CUDA 10.x 那样:每升一个 minor 就必须升 driver。
安装#
# ubuntu 20.04, x86_64
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.0-1_all.deb
sudo dpkg -i cuda-keyring_1.0-1_all.deb
sudo apt-get update
sudo apt-get -y install cuda参考:
apt install linux-headers-$(uname -r)cuda 12.8#
# https://developer.nvidia.com/cuda-12-8-0-download-archive
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-8升级 cuda#
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/3bf863cc.pub
sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /"
wget https://developer.download.nvidia.com/compute/cuda/12.0.0/local_installers/cuda-repo-ubuntu2004-12-0-local_12.0.0-525.60.13-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2004-12-0-local_12.0.0-525.60.13-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2004-12-0-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda22.04#
# https://developer.nvidia.com/cuda-downloads?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=22.04&target_type=deb_local
# 安装
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/13.0.0/local_installers/cuda-repo-ubuntu2204-13-0-local_13.0.0-580.65.06-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2204-13-0-local_13.0.0-580.65.06-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2204-13-0-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda-toolkit-13-0
# 卸载
# 卸载 CUDA Toolkit 13.0 主包
sudo apt purge cuda-toolkit-13-0 -y
# 移除所有 CUDA 关联包(含驱动以外的依赖库)
sudo apt --purge remove "cuda*" "libcudnn*" "nvidia-cuda-toolkit" -y
# 清理残留依赖
sudo apt autoremove && sudo apt autoclean
# 确认无 CUDA 残留包
dpkg -l | grep -i cuda # 应无输出
# 强制卸载残留包(忽略依赖检查)
sudo dpkg --purge --force-all libnvptxcompiler-13-0# https://developer.nvidia.com/cuda-12-4-0-download-archive?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=22.04&target_type=deb_local
# 安装
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda-repo-ubuntu2204-12-4-local_12.4.0-550.54.14-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2204-12-4-local_12.4.0-550.54.14-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2204-12-4-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-4安装 nvcc#
apt install nvidia-cuda-toolkit安装 cuda 11.4#
Cleaning remaining files#
# Deleting any NVIDIA/CUDA packages you may already have installed
sudo rm /etc/apt/sources.list.d/cuda*
sudo apt remove --autoremove nvidia-cuda-toolkit
sudo apt remove --autoremove nvidia-*
# Deleting any remaining Cuda files on /usr/local/
sudo rm -rf /usr/local/cuda*
# Purge any remaining NVIDIA configuration files
sudo apt-get purge nvidia*
# updating and deleting unnecessary dependencies.
sudo apt-get update
sudo apt-get autoremove
sudo apt-get autoclean
# For 18.04
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin
sudo mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/11.4.0/local_installers/cuda-repo-ubuntu1804-11-4-local_11.4.0-470.42.01-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu1804-11-4-local_11.4.0-470.42.01-1_amd64.deb
sudo apt-key add /var/cuda-repo-ubuntu1804-11-4-local/7fa2af80.pub
sudo apt-get update
sudo apt-get -y install cuda
# For 20.04
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/11.4.0/local_installers/cuda-repo-ubuntu2004-11-4-local_11.4.0-470.42.01-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2004-11-4-local_11.4.0-470.42.01-1_amd64.deb
sudo apt-key add /var/cuda-repo-ubuntu2004-11-4-local/7fa2af80.pub
sudo apt-get update
sudo apt-get -y install cuda
# 配置 path
cat << 'EOF' >> ~/.zshrc
# set PATH for cuda 11.4 installation
if [ -d "/usr/local/cuda-11.4/bin/" ]; then
export PATH=/usr/local/cuda-11.4/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-11.4/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
fi
EOF
zsh
# check
nvidia-smi
nvcc -V
# nvcc --version参考:
测试 cuda#
vi kernel.cu
nvcc -o kernel kernel.cu
./kernel
# 输出
# Max error: 0.000000#include <stdio.h>
__global__
void saxpy(int n, float a, float *x, float *y)
{
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n) y[i] = a*x[i] + y[i];
}
int main(void)
{
int N = 1<<20;
float *x, *y, *d_x, *d_y;
x = (float*)malloc(N*sizeof(float));
y = (float*)malloc(N*sizeof(float));
cudaMalloc(&d_x, N*sizeof(float));
cudaMalloc(&d_y, N*sizeof(float));
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
cudaMemcpy(d_x, x, N*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_y, y, N*sizeof(float), cudaMemcpyHostToDevice);
// Perform SAXPY on 1M elements
saxpy<<<(N+255)/256, 256>>>(N, 2.0f, d_x, d_y);
cudaMemcpy(y, d_y, N*sizeof(float), cudaMemcpyDeviceToHost);
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = max(maxError, abs(y[i]-4.0f));
printf("Max error: %f\n", maxError);
cudaFree(d_x);
cudaFree(d_y);
free(x);
free(y);
}CUDA vs cuDNN vs cuBLAS#
- cuDNN 是基于 CUDA 的深度学习 GPU 加速库,有了它才能在 GPU 上完成深度学习的计算
- 只要把 cuDNN 文件复制到 CUDA 的对应文件夹里就可以,即是所谓插入式设计
- cuBLAS (
CUDA Basic Linear Algebra Subroutine library) CUDA 基本线性代数子程序库 - cutlass 仅支持矩阵乘法运算,不支持卷积算子,从而难以直接应用到计算机视觉领域的推理部署中
查看 cuDNN 版本#
# 查看cuDNN版本
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
例如:
#define CUDNN_MAJOR 8
#define CUDNN_MINOR 2
#define CUDNN_PATCHLEVEL 4
表示当前使用的是cuDNN 8.2.4 版本
叶王 © 2013-2026 版权所有。如果本文档对你有所帮助,可以请作者喝饮料。